
AI-ondersteunde codering en platforms voor het genereren van AI-apps hebben voor een ongekende golf van softwareontwikkeling gezorgd. Bedrijven worden nu geconfronteerd met een snelle groei in zowel het aantal applicaties als het tempo van de veranderingen binnen die applicaties. Beveiligings- en privacyteams staan onder grote druk omdat de oppervlakte die ze moeten bestrijken snel groeit terwijl hun personeelsbestand grotendeels onveranderd blijft.
Bestaande oplossingen voor gegevensbeveiliging en privacy zijn dat ook reactief voor dit nieuwe tijdperk. Velen beginnen met gegevens die al tijdens de productie zijn verzameld, wat vaak te laat is. Deze oplossingen missen vaak verborgen datastromen naar derde partijen en AI-integraties, en voor de data-sinks die ze wel dekken, helpen ze risico’s te detecteren, maar ze niet te voorkomen. De vraag is of veel van deze problemen vroegtijdig kunnen worden voorkomen. Het antwoord is ja. Preventie is mogelijk door detectie- en beheercontroles rechtstreeks in de ontwikkeling in te bedden. HoundDog.ai biedt een privacycodescanner die precies voor dit doel is gebouwd.
Problemen met gegevensbeveiliging en privacy die proactief kunnen worden aangepakt
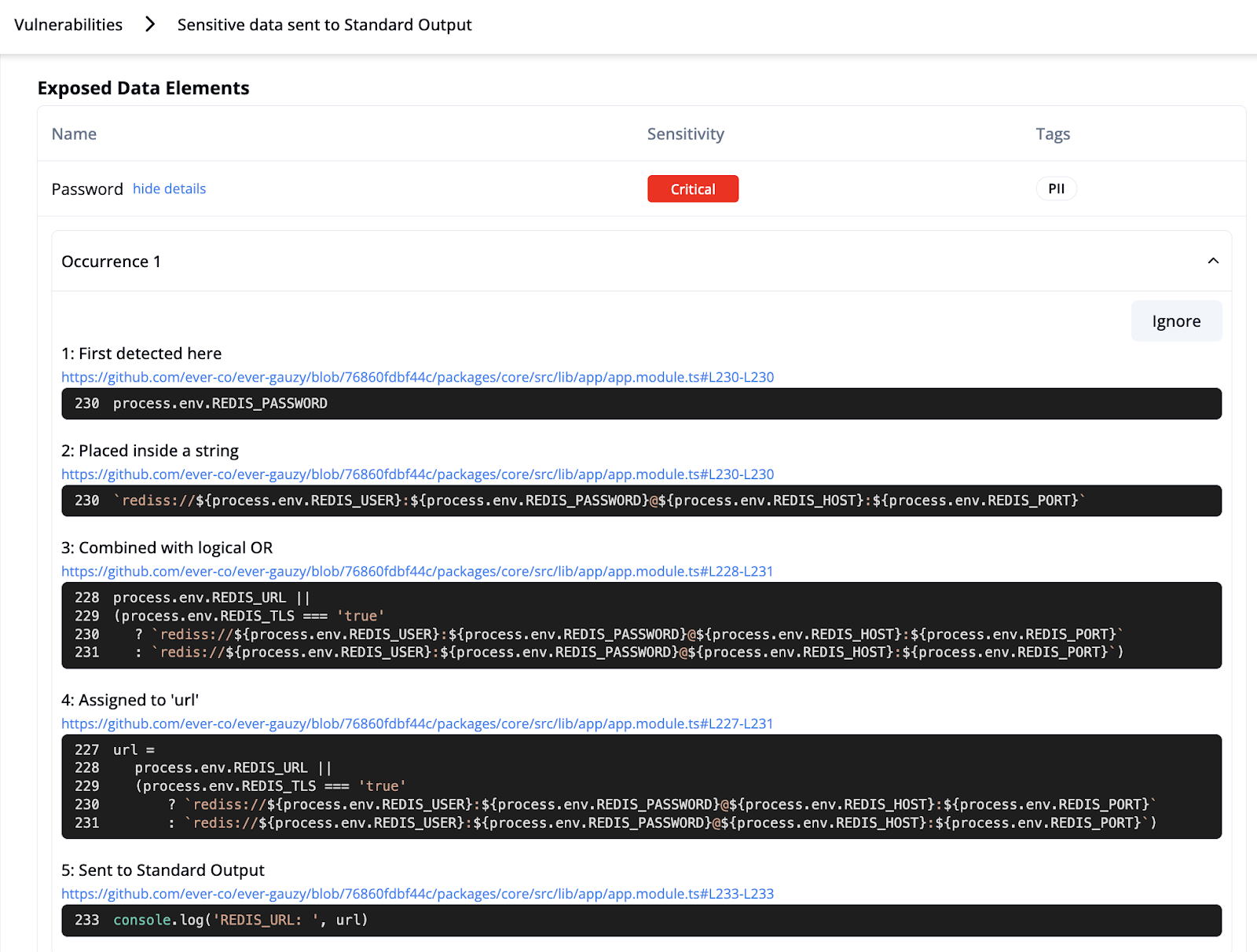
Het blootstellen van gevoelige gegevens in logboeken blijft een van de meest voorkomende en kostbare problemen
Wanneer gevoelige gegevens in logboeken verschijnen, is het vertrouwen op DLP-oplossingen reactief, onbetrouwbaar en traag. Teams kunnen wekenlang bezig zijn met het opschonen van logboeken, het identificeren van de blootstelling op de systemen die ze hebben opgenomen, en het achteraf herzien van de code. Deze incidenten beginnen vaak met eenvoudige vergissingen van de ontwikkelaar, zoals het gebruik van een besmette variabele of het afdrukken van een volledig gebruikersobject in een debug-functie. Naarmate de technische teams groter worden dan twintig ontwikkelaars, wordt het bijhouden van alle codepaden lastig en komen deze vergissingen steeds vaker voor.
Onnauwkeurige of verouderde datakaarten brengen ook aanzienlijke privacyrisico’s met zich mee
Een kernvereiste in de AVG en de Amerikaanse privacyframeworks is de noodzaak om verwerkingsactiviteiten te documenteren met details over de soorten persoonlijke gegevens die worden verzameld, verwerkt, opgeslagen en gedeeld. Datakaarten worden vervolgens meegenomen in verplichte privacyrapporten zoals Records of Processing Activity (RoPA), Privacy Impact Assessments (PIA) en Data Protection Impact Assessments (DPIA). Deze rapporten moeten de rechtsgrondslagen voor de verwerking documenteren, de naleving van de beginselen voor gegevensminimalisatie en -bewaring aantonen en ervoor zorgen dat de betrokkenen transparant zijn en hun rechten kunnen uitoefenen. In snel veranderende omgevingen raken datakaarten echter snel verouderd. Traditionele workflows in GRC-tools vereisen dat privacyteams applicatie-eigenaren herhaaldelijk interviewen, een proces dat zowel langzaam als foutgevoelig is. Belangrijke details worden vaak over het hoofd gezien, vooral in bedrijven met honderden of duizenden codeopslagplaatsen. Op productie gerichte privacyplatforms bieden slechts gedeeltelijke automatisering omdat ze proberen gegevensstromen af te leiden op basis van gegevens die al in productiesystemen zijn opgeslagen. Ze kunnen SDK’s, abstracties en integraties vaak niet zien die in de code zijn ingebed. Deze blinde vlekken kunnen leiden tot schendingen van gegevensverwerkingsovereenkomsten of onnauwkeurige mededelingen in privacyverklaringen. Omdat deze platforms problemen pas detecteren nadat er al gegevens binnenkomen, bieden ze geen proactieve controles die risicovol gedrag überhaupt voorkomen.
Een andere grote uitdaging zijn de wijdverbreide experimenten met AI in codebases
Veel bedrijven hebben beleid dat AI-diensten in hun producten beperkt. Maar bij het scannen van hun repository’s is het gebruikelijk om in 5% tot 10% van de repository’s AI-gerelateerde SDK’s zoals LangChain of LlamaIndex aan te treffen. Privacy- en beveiligingsteams moeten vervolgens begrijpen welke gegevenstypen naar deze AI-systemen worden verzonden en of gebruikerskennisgevingen en rechtsgrondslagen deze stromen dekken. Het gebruik van AI zelf is niet het probleem. Het probleem ontstaat wanneer ontwikkelaars AI zonder toezicht introduceren. Zonder proactieve technische handhaving moeten teams deze stromen met terugwerkende kracht onderzoeken en documenteren, wat tijdrovend en vaak onvolledig is. Naarmate het aantal AI-integraties toeneemt, groeit ook het risico op niet-naleving.
Wat is HoundDog.ai
HoundDog.ai biedt een op privacy gerichte statische codescanner die voortdurend de broncode analyseert om gevoelige gegevensstromen tussen opslagsystemen, AI-integraties en services van derden te documenteren. De scanner identificeert privacyrisico’s en gevoelige datalekken al vroeg in de ontwikkeling, voordat code wordt samengevoegd en voordat gegevens ooit worden verwerkt. De motor is gebouwd in Rust, wat geheugenveilig is, en is licht en snel. Het scant miljoenen regels code in minder dan een minuut. De scanner is onlangs geïntegreerd met Replit, het platform voor het genereren van AI-apps dat door 45 miljoen makers wordt gebruikt, waardoor inzicht wordt verkregen in de privacyrisico’s van de miljoenen applicaties die door het platform worden gegenereerd.
Belangrijkste mogelijkheden
AI-governance en risicobeheer van derden
Identificeer met veel vertrouwen AI- en integraties van derden die in code zijn ingebed, inclusief verborgen bibliotheken en abstracties die vaak worden geassocieerd met schaduw-AI.

Proactieve detectie van gevoelige datalekken
Integreer privacy in alle fasen van de ontwikkeling, van IDE-omgevingen, met extensies beschikbaar voor VS Code, IntelliJ, Cursor en Eclipse, tot CI-pijplijnen die directe broncode-integraties gebruiken en automatisch CI-configuraties pushen als directe commits of pull-aanvragen die goedkeuring vereisen. Volg meer dan 100 soorten gevoelige gegevens, waaronder persoonlijk identificeerbare informatie (PII), beschermde gezondheidsinformatie (PHI), kaarthoudergegevens (CHD) en authenticatietokens, en volg ze tijdens transformaties naar risicovolle sinks zoals LLM-prompts, logs, bestanden, lokale opslag en SDK’s van derden.
Bewijs genereren voor naleving van de privacy
Genereer automatisch op bewijs gebaseerde datakaarten die laten zien hoe gevoelige gegevens worden verzameld, verwerkt en gedeeld. Produceer audit-ready Records van verwerkingsactiviteiten (RoPA), Privacy Impact Assessments (PIA) en Data Protection Impact Assessments (DPIA), vooraf gevuld met gedetecteerde gegevensstromen en privacyrisico’s geïdentificeerd door de scanner.

Waarom dit ertoe doet
Bedrijven moeten blinde vlekken wegnemen
Een privacyscanner die op codeniveau werkt, biedt inzicht in integraties en abstracties die productietools missen. Dit omvat verborgen SDK’s, bibliotheken van derden en AI-frameworks die pas in productiescans verschijnen als het te laat is.
Teams moeten ook privacyrisico’s onderkennen voordat deze zich voordoen
Authenticatietokens in platte tekst of gevoelige gegevens in logboeken, of niet-goedgekeurde gegevens die naar integraties van derden worden verzonden, moeten bij de bron worden gestopt. Preventie is de enige betrouwbare manier om incidenten en lacunes in de naleving te voorkomen.
Privacyteams hebben nauwkeurige en voortdurend bijgewerkte datakaarten nodig
Het geautomatiseerd genereren van RoPA’s, PIA’s en DPIA’s op basis van codebewijs zorgt ervoor dat de documentatie gelijke tred houdt met de ontwikkeling, zonder herhaalde handmatige interviews of spreadsheet-updates.
Vergelijking met andere tools
Privacy- en beveiligingsteams gebruiken een mix van tools, maar elke categorie heeft fundamentele beperkingen.
Statische analysetools voor algemene doeleinden bieden aangepaste regels, maar ontberen privacybewustzijn. Ze behandelen verschillende gevoelige datatypen als gelijkwaardig en kunnen de moderne AI-gestuurde datastromen niet begrijpen. Ze vertrouwen op eenvoudige patroonafstemming, die luidruchtige waarschuwingen produceert en voortdurend onderhoud vereist. Ze missen ook elke ingebouwde nalevingsrapportage.
Privacyplatforms na de implementatie brengen gegevensstromen in kaart op basis van informatie die is opgeslagen in productiesystemen. Ze kunnen geen integraties of stromen detecteren die nog geen gegevens in die systemen hebben opgeleverd en kunnen geen abstracties zien die in code verborgen zijn. Omdat ze na de implementatie actief zijn, kunnen ze geen risico’s voorkomen en zorgen ze voor een aanzienlijke vertraging tussen de introductie en detectie van problemen.
Hulpmiddelen voor reactieve gegevensverliespreventie komen pas in actie nadat gegevens zijn gelekt. Ze hebben geen inzicht in de broncode en kunnen de hoofdoorzaken niet identificeren. Wanneer gevoelige gegevens logboeken of transmissies bereiken, verloopt het opruimen traag. Teams zijn vaak weken bezig met het herstellen en beoordelen van de blootstelling aan veel systemen.
HoundDog.ai verbetert deze benaderingen door een statische analyse-engine te introduceren die speciaal is gebouwd voor privacy. Het voert diepgaande interprocedurele analyses uit tussen bestanden en functies om gevoelige gegevens te traceren, zoals persoonlijk identificeerbare informatie (PII), beschermde gezondheidsinformatie (PHI), kaarthoudergegevens (CHD) en authenticatietokens. Het begrijpt transformaties, saneringslogica en controlestromen. Het identificeert wanneer gegevens risicovolle sinks bereiken, zoals logboeken, bestanden, lokale opslag, SDK’s van derden en LLM-prompts. Het geeft prioriteit aan problemen op basis van gevoeligheid en daadwerkelijk risico in plaats van eenvoudige patronen. Het bevat native ondersteuning voor meer dan 100 gevoelige gegevenstypen en maakt maatwerk mogelijk.
HoundDog.ai detecteert ook zowel directe als indirecte AI-integraties vanuit de broncode. Het identificeert onveilige of niet-opgeschoonde gegevensstromen in prompts en stelt teams in staat toelatingslijsten af te dwingen die definiëren welke gegevenstypen mogen worden gebruikt met AI-services. Dit proactieve model blokkeert de onveilige promptconstructie voordat de code wordt samengevoegd, waardoor handhaving wordt geboden waar runtime-filters niet aan kunnen voldoen.
Naast detectie automatiseert HoundDog.ai de creatie van privacydocumentatie. Het produceert een altijd nieuwe inventaris van interne en externe gegevensstromen, opslaglocaties en afhankelijkheden van derden. Het genereert audit-ready records van verwerkingsactiviteiten en privacy-impactbeoordelingen, gevuld met echt bewijsmateriaal en afgestemd op raamwerken zoals FedRAMP, DoD RMF, HIPAA en NIST 800-53.
Succes van de klant
HoundDog.ai wordt al gebruikt door Fortune 1000-bedrijven in de gezondheidszorg en financiële dienstverlening en scant duizenden opslagplaatsen. Deze organisaties verminderen de overhead voor het in kaart brengen van data, signaleren privacyproblemen al vroeg in de ontwikkeling en handhaven de compliance zonder de engineering te vertragen.
| Gebruikscasus | Klantresultaten |
| Slash-overhead voor gegevenstoewijzing | Fortune 500-gezondheidszorg
|
| Minimaliseer gevoelige gegevenslekken in logboeken | Eenhoorn Fintech
|
| Continue naleving van DPA’s bij AI en integraties van derden | Serie B Fintech
|
Herhaling
De meest zichtbare implementatie vindt plaats in Replit, waar de scanner de meer dan 45 miljoen gebruikers van het AI-platform voor het genereren van apps helpt beschermen. Het identificeert privacyrisico’s en traceert gevoelige gegevensstromen tussen miljoenen door AI gegenereerde applicaties. Hierdoor kan Replit privacy rechtstreeks inbedden in de workflow voor het genereren van apps, zodat privacy een kernfunctie wordt in plaats van een bijzaak.

Door privacy naar de vroegste ontwikkelingsfasen te verplaatsen en continue zichtbaarheid, handhaving en documentatie te bieden, maakt HoundDog.ai het voor teams mogelijk om veilige en compatibele software te bouwen met de snelheid die moderne AI-gestuurde ontwikkeling vereist.