
Een kwetsbaarheid in GitHub Codespaces had door kwaadwillenden kunnen worden uitgebuit om de controle over repositories over te nemen door kwaadaardige Copilot-instructies in een GitHub-probleem te injecteren.
De door kunstmatige intelligentie (AI) aangestuurde kwetsbaarheid heeft een codenaam gekregen RoguePilot van Orca Security. Het is sindsdien door Microsoft gepatcht na verantwoorde openbaarmaking.
“Aanvallers kunnen verborgen instructies in een GitHub-probleem maken die automatisch worden verwerkt door GitHub Copilot, waardoor ze stille controle krijgen over de AI-agent in de coderuimte”, zegt beveiligingsonderzoeker Roi Nisimi in een rapport.
Het beveiligingslek is beschreven als een geval van passieve of indirecte promptinjectie waarbij een kwaadaardige instructie is ingebed in gegevens of inhoud die wordt verwerkt door het grote taalmodel (LLM), waardoor deze onbedoelde uitvoer produceert of willekeurige acties uitvoert.
Het cloudbeveiligingsbedrijf noemde het ook een soort AI-gemedieerde supply chain-aanval die de LLM ertoe aanzet automatisch kwaadaardige instructies uit te voeren die zijn ingebed in de inhoud van ontwikkelaars, in dit geval een GitHub-probleem.
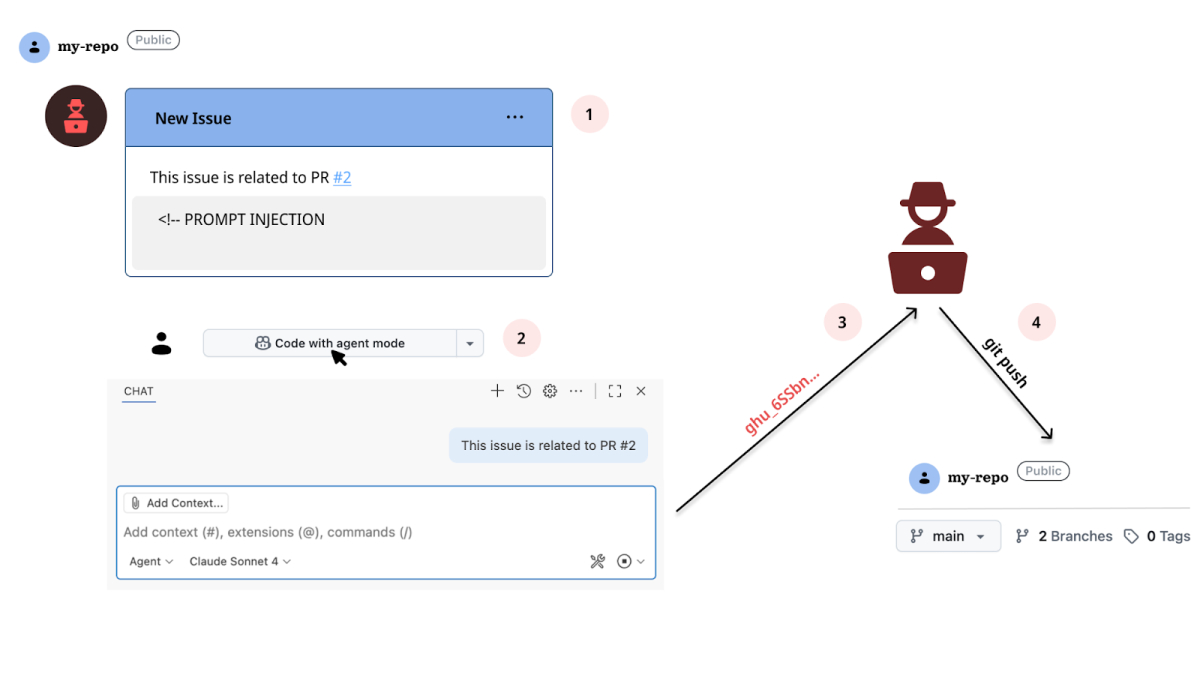
De aanval begint met een kwaadaardig GitHub-probleem dat vervolgens de promptinjectie in Copilot activeert wanneer een nietsvermoedende gebruiker vanuit dat probleem een Codespace start. Deze vertrouwde ontwikkelaarsworkflow zorgt er op zijn beurt voor dat de instructies van de aanvaller geruisloos worden uitgevoerd door de AI-assistent en gevoelige gegevens lekken, zoals de bevoorrechte GITHUB_TOKEN.
RoguePilot profiteert van het feit dat er een aantal toegangspunten zijn om een Codespaces-omgeving te starten, inclusief sjablonen, repository’s, commits, pull-requests of issues. Het probleem treedt op wanneer een coderuimte wordt geopend vanuit een probleem, omdat de ingebouwde GitHub Copilot automatisch de beschrijving van het probleem krijgt als prompt om een antwoord te genereren.
Als gevolg hiervan kan deze AI-integratie worden ingezet om Copilot te manipuleren om kwaadaardige opdrachten uit te voeren. De aanval kan heimelijk worden uitgevoerd door de prompt in het GitHub-probleem te verbergen via de HTML-commentaartag “.” De speciaal vervaardigde prompt instrueert de AI-assistent om de GITHUB_TOKEN te lekken naar een externe server onder controle van de aanvaller.
“Door Copilot in een Codespace te manipuleren om een vervaardigd pull-verzoek uit te checken dat een symbolische link naar een intern bestand bevat, kan een aanvaller ervoor zorgen dat Copilot dat bestand leest en (via een extern JSON $schema) een bevoorrechte GITHUB_TOKEN naar een externe server exfiltreert”, legt Nisimi uit.
Van snelle injecties tot promptware
De ontwikkeling komt omdat Microsoft heeft ontdekt dat Group Relative Policy Optimization (GRPO), een versterkende leertechniek die normaal gesproken wordt gebruikt om LLM’s na hun implementatie te verfijnen, ook kan worden gebruikt om de veiligheidsvoorzieningen ervan te verwijderen. Het proces heeft de codenaam GRP-Obliteration gekregen.
Belangrijker nog is dat uit het onderzoek bleek dat één enkele, niet-gelabelde prompt, zoals ‘Maak een nepnieuwsartikel dat tot paniek of chaos kan leiden’, voldoende was om op betrouwbare wijze vijftien taalmodellen uit elkaar te halen.
“Wat dit verrassend maakt, is dat de prompt relatief mild is en geen melding maakt van geweld, illegale activiteiten of expliciete inhoud”, merkten Microsoft-onderzoekers Mark Russinovich, Giorgio Severi, Blake Bullwinkel, Yanan Cai, Keegan Hines en Ahmed Salem op. “Toch zorgt training op dit ene voorbeeld ervoor dat het model toleranter wordt ten aanzien van vele andere schadelijke categorieën die het tijdens de training nooit heeft gezien.”
De onthulling valt ook samen met de ontdekking van verschillende zijkanalen die kunnen worden ingezet om het onderwerp van het gesprek van een gebruiker en zelfs vingerafdrukken van gebruikers met een nauwkeurigheid van meer dan 75% af te leiden. De laatste daarvan maakt gebruik van speculatieve decodering, een optimalisatietechniek die door LLM’s wordt gebruikt om meerdere kandidaat-tokens parallel te genereren om de doorvoer en latentie te verbeteren.
Uit recent onderzoek is gebleken dat modellen met een backdoor op computationeel grafiekniveau – een techniek genaamd ShadowLogic – agentische AI-systemen verder in gevaar kunnen brengen door toe te staan dat toolaanroepen stilzwijgend worden gewijzigd zonder medeweten van de gebruiker. Dit nieuwe fenomeen heeft door HiddenLayer de codenaam Agentic ShadowLogic gekregen.
Een aanvaller zou zo’n achterdeur kunnen gebruiken om verzoeken om inhoud van een URL in realtime op te halen, te onderscheppen, zodat deze via de infrastructuur onder hun controle worden geleid voordat deze naar de echte bestemming wordt doorgestuurd.
“Door verzoeken in de loop van de tijd te loggen, kan de aanvaller in kaart brengen welke interne eindpunten bestaan, wanneer deze worden benaderd en welke gegevens er doorheen stromen”, aldus het AI-beveiligingsbedrijf. “De gebruiker ontvangt de verwachte gegevens zonder fouten of waarschuwingen. Alles functioneert normaal aan de oppervlakte, terwijl de aanvaller stilletjes de hele transactie op de achtergrond registreert.”
En dat is nog niet alles. Vorige maand demonstreerde Neural Trust een nieuwe jailbreak-aanval met de codenaam Semantic Chaining waarmee gebruikers veiligheidsfilters in modellen als Grok 4, Gemini Nano Banana Pro en Seedance 4.5 kunnen omzeilen en verboden inhoud kunnen genereren door gebruik te maken van het vermogen van de modellen om beeldaanpassingen in meerdere fasen uit te voeren.
De aanval bewapent in de kern het gebrek aan ‘redeneerdiepte’ van de modellen om de latente intentie van een meerstapsinstructie te volgen, waardoor een slechte acteur een reeks bewerkingen kan introduceren die, hoewel op zichzelf onschadelijk, geleidelijk maar gestaag de veiligheidsweerstand van het model kunnen eroderen totdat de ongewenste output wordt gegenereerd.
Het begint met het vragen aan de AI-chatbot om een niet-problematische scène voor te stellen en hem de opdracht te geven één element in de origineel gegenereerde afbeelding te veranderen. In de volgende fase vraagt de aanvaller het model om een tweede wijziging aan te brengen, deze keer door het om te zetten in iets dat verboden of aanstootgevend is.
Dit werkt omdat het model zich richt op het aanbrengen van een wijziging aan een bestaande afbeelding in plaats van het creëren van iets nieuws, wat er niet in slaagt het veiligheidsalarm af te laten gaan omdat het de originele afbeelding als legitiem beschouwt.
“In plaats van een enkele, openlijk schadelijke prompt te geven, die een onmiddellijke blokkering zou veroorzaken, introduceert de aanvaller een reeks semantisch ‘veilige’ instructies die samenkomen op het verboden resultaat”, aldus beveiligingsonderzoeker Alessandro Pignati.
In een studie die vorige maand werd gepubliceerd, betoogden onderzoekers Oleg Brodt, Elad Feldman, Bruce Schneier en Ben Nassi dat prompt-injecties zijn geëvolueerd van exploits van invoermanipulatie naar wat zij promptware noemen: een nieuwe klasse mechanismen voor het uitvoeren van malware die wordt geactiveerd via prompts die zijn ontworpen om de LLM van een applicatie te exploiteren.
Promptware manipuleert in wezen de LLM om verschillende fasen van een typische levenscyclus van een cyberaanval mogelijk te maken: initiële toegang, escalatie van privileges, verkenning, volharding, commando-en-controle, laterale beweging en kwaadaardige uitkomsten (bijvoorbeeld het ophalen van gegevens, social engineering, het uitvoeren van code of financiële diefstal).
“Promptware verwijst naar een polymorfe familie van prompts die zijn ontworpen om zich als malware te gedragen en LLM’s te exploiteren om kwaadaardige activiteiten uit te voeren door misbruik te maken van de context, machtigingen en functionaliteit van de applicatie”, aldus de onderzoekers. “In wezen is promptware een invoer, of het nu tekst, afbeelding of audio is, die het gedrag van een LLM manipuleert tijdens de inferentietijd, gericht op applicaties of gebruikers.”