
Grote taalmodellen blijven webadressen bedenken die niet bestaan. Aanvallers zijn begonnen met het kopen van deze verzonnen domeinen voordat iemand anders dat kan, en hosten er vervolgens phishing-pagina’s op om verkeer te vangen dat AI-tools hun kant op wijzen.
Unit 42 van Palo Alto Networks noemt de truc fantoom hurkenen uit nieuw onderzoek blijkt dat dit al in het wild gebeurt.
De reden dat het ertoe doet is vertrouwen. Ontwikkelaars en AI-assistenten beschouwen de verbanden die een model teruggeeft steeds meer als reëel. Wanneer een model een domein uitvindt dat nog niet bestaat, erft degene die het als eerste registreert al dat misplaatste vertrouwen, zonder dat phishing-e-mail en kwaadaardige advertenties nodig zijn.
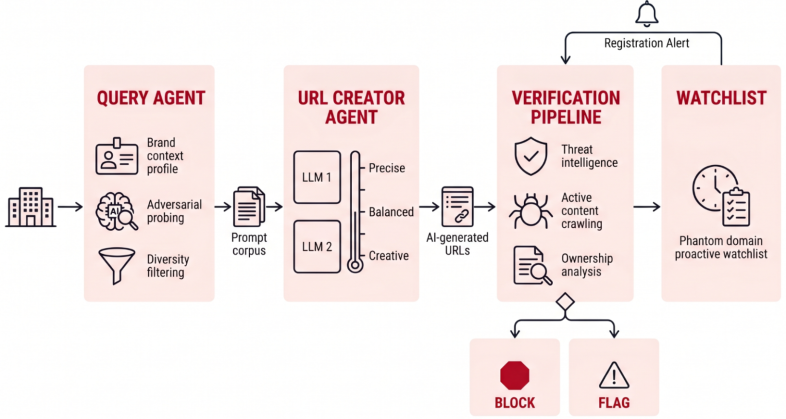
Om het probleem te meten, stelde Unit 42 twee AI-modellen 685.339 vragen over 913 bekende merken in de technologie-, financiële, gezondheidszorg-, overheids-, gok- en andere sectoren.
De modellen produceerden 2,1 miljoen links. Bedreigingsinformatie heeft 13.229 van hen al aangemerkt als ronduit kwaadaardig, wat betekent dat de AI bekende slechte adressen uitdeelde. Ongeveer 250.000 van de uitgevonden domeinen hadden nog geen eigenaar, elk een doelwit voor degene die het als eerste registreerde.
Hoe fantoomhurken werkt
De aanval werkt omdat een gloednieuw domein geen reputatie heeft. Blokkeerlijsten, bedreigingsfeeds en reputatiescores hebben allemaal een site nodig die zich een tijdje misdraagt voordat ze deze markeren.
Een nieuw geregistreerd fantoomdomein heeft zo’n record niet, dus deze filters hebben niets te markeren. Tegen de tijd dat ze de achterstand inhalen, is het slachtoffer al naar de site gestuurd via een tool die ze vertrouwen.
Twee details maken het nog erger. De nepdomeinen zaten niet in de trainingsgegevens: beide modellen werden verzonden voordat de echte kwaadaardige sites bestonden, dus de adressen komen uit de eigen taalpatronen van de modellen en niet uit het geheugen. En die patronen zijn consistent.
Verschillende modellen bedenken vaak hetzelfde nepdomein voor dezelfde vraag, waardoor het volgende doelwit van een aanvaller gemakkelijk te raden is. Het verhogen van de ‘creativiteit’-instelling van een model leverde alleen maar meer verzonnen domeinen op. Zoals de onderzoekers van Unit 42 het uitdrukten, exploiteert de vector “een structurele eigenschap van LLM-architecturen die inherent niet te patchen is.”
Twee waargenomen gevallen
Twee gevallen tonen de volledige lus. Op 8 maart 2026 voorspelde het systeem van Unit 42 dat AI-modellen een domein zouden uitvinden dat lijkt op de online marktplaats van een nationale postdienst. Beide modellen genereerden het bij elke temperatuurinstelling, een sterk teken dat ze de nepsite als feit behandelden.
Drieëntwintig dagen later, op 31 maart, registreerde een aanvaller dat exacte domein en zette een phishing-kit op met de naam Montana Empire. De kit kopieerde de echte winkelpui in realtime. Er werden kaartnummers, bankoverschrijvingsgegevens en nationale identiteitsgegevens gestolen.
Met een Telegram-bot kan de operator de eenmalige toegangscodes van slachtoffers handmatig goedkeuren. De weggeefactie: overgebleven projectbestanden en sessielogboeken lieten zien dat de crimineel de kit had gebouwd met een AI-coderingsassistent. Aanvaller en verdediger bereikten hetzelfde nepdomein op dezelfde manier, door een AI te vragen.
In het tweede geval markeerde Unit 42 een gehallucineerd postdomein 51 dagen voordat een aanvaller het registreerde. De aanvaller verpakte het vervolgens in een pixel-perfecte merkkloon, voegde een valse beoordeling van 4,8 sterren toe en een claim van meer dan twee miljoen gebruikers, en gebruikte het om een kwaadaardige Android-app te pushen.
Andere gedetecteerde domeinen imiteerden een grote bank in de VAE die een aanvaller al bijna een jaar misbruikte, een Europese bank en sites voor sportweddenschappen gericht op gebruikers in Bangladesh.
Een oude truc met een nieuw doel
Phantom kraken is de domeinversie van slordigwaar aanvallers de valse softwarepakketnamen registreren die AI-coderingstools verzinnen. Dat is niet hypothetisch.
Uit een groot USENIX-onderzoek bleek dat codegenererende modellen routinematig pakketnamen suggereren die niet bestaan, en de PhantomRaven-campagne veranderde precies dat gedrag in malware verborgen in 126 npm-pakketten met meer dan 86.000 installaties.
Het wijst op een grotere verschuiving: modeloutput wordt input. Ontwikkelaars, agenten en beveiligingsteams handelen op basis van door AI gegenereerde links en namen voordat iemand ze verifieert, en AI blijft de tijd die verdedigers hebben om te reageren verkorten.
Het komt ook terecht in een wereld waar phishing door merkimitatie nu een betaalde dienst is, waarbij kits als Lucid en Lighthouse 17.500 nepdomeinen tegen 316 merken in 74 landen opnemen.
Wat te doen
Omdat modellen consequent hallucineren, kunnen beveiligingsteams in kaart brengen welke nepdomeinen een model waarschijnlijk zal produceren en opletten of iedereen deze registreert, vaak met wekenlange waarschuwing. Voor alle anderen zijn de praktische stappen eenvoudig:
- Vertrouw een link niet alleen omdat een AI deze heeft gegeven. Bevestig dat het domein het echte, officiële domein is voordat u een wachtwoord typt of in code plakt.
- Voorkom dat AI-agents zonder controle automatisch door modellen gegenereerde links openen of downloaden. Een agent heeft geen instinct om te aarzelen zoals iemand dat zou kunnen doen.
- Beschouw alles wat een model schrijft als een niet-geverifieerd concept en niet als een autoriteit.
Dat venster staat open en het beloont degene die als eerste beweegt. De echte vraag, zoals Unit 42 het formuleert, is eenvoudigweg of verdedigers of aanvallers deze domeinen eerder bereiken.