Nieuw Microsoft-onderzoek laat zien hoe aanvallers AI-agents kunnen kapen die namens een gebruiker handelen, met behulp van niets meer dan een vergiftigde toolbeschrijving om de agent stilletjes bedrijfsgegevens aan een buitenstaander te laten overhandigen.
De truc is dat de agent nooit een regel overtreedt. Elke stap ziet er routinematig uit, dus in een standaardconfiguratie kan er geen alarm afgaan.
Het werk is afkomstig van Microsoft Incident Response en zijn Defender-beveiligingsonderzoeksteam, en het komt terecht nu bedrijven AI meer gaan laten doen dan lezen en samenvatten.
Wat verandert er als een agent kan optreden?
Tot voor kort was het AI-risico op de werkplek vooral gebaseerd op wat een model las en schreef. Een vergiftigd document kon een antwoord vertekenen, en dat was meestal waar het eindigde.
Agenten zijn anders. Microsoft 365 Copilot kan e-mail verzenden, bestanden maken en agenda’s wijzigen. Aangepaste agenten die zijn ingebouwd in Copilot Studio of Azure AI Foundry kunnen bedrijfssystemen bereiken en zelfstandig taken in meerdere stappen uitvoeren.
Dezelfde injectietruc die een samenvatting vertekent, leidt nu tot een actie. Tegen een lezer verandert een aanval de uitvoer. Tegenover een agent verandert het wat de software feitelijk doet.
Deze agenten bereiken bedrijfssystemen via MCP, het Model Context Protocol, een open protocol waarmee een AI externe tools kan aanroepen zoals een app een API aanroept. Microsoft noemt het het snelst groeiende onderdeel van de AI-toeleveringsketen, waardoor het een steeds groter aanvalsoppervlak wordt.
Hoe de aanval werkt
Elke MCP-tool wordt geleverd met een beschrijving: een paar regels platte tekst die de agent vertellen wat de tool doet en wanneer hij deze moet gebruiken. De agent leest die tekst om te beslissen hoe hij moet handelen. Dat is de hele zwakte. De beschrijving bestaat uit slechts woorden, en woorden kunnen instructies bevatten.
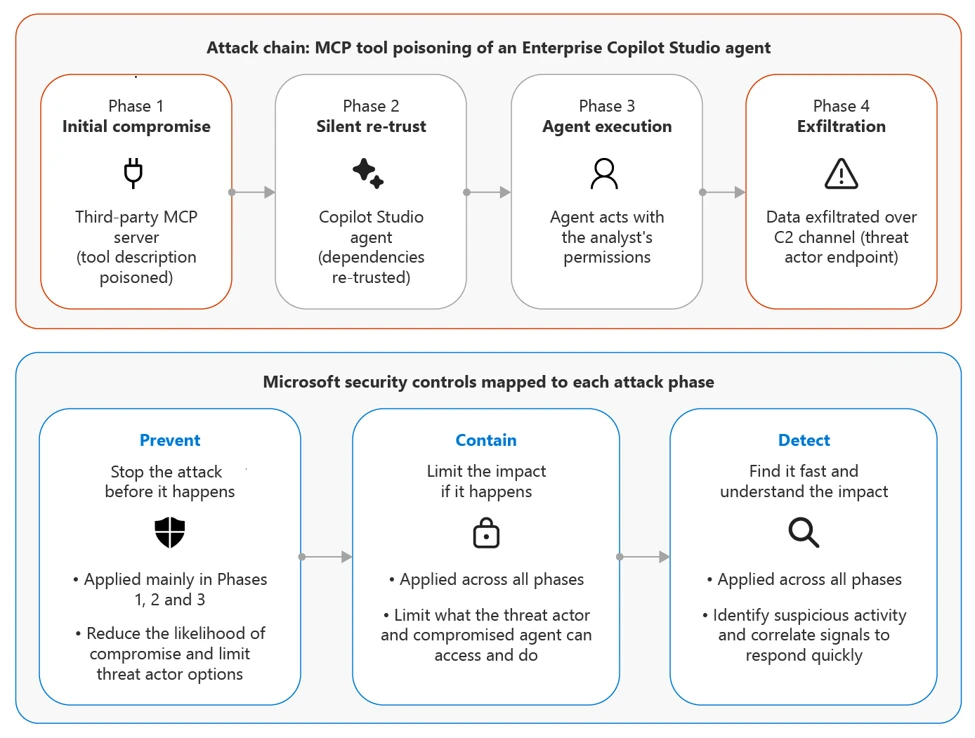
Microsoft loopt er doorheen met een factuurvoorbeeld, gebouwd om het patroon te laten zien in plaats van een genoemd slachtoffer te melden. Een financieel team schakelt een agent in om leveranciersfacturen af te handelen. Het maakt verbinding met drie tools, waaronder een service voor ‘factuurverrijking’ van derden die is goedgekeurd voor gebruik, maar nooit een echte veiligheidsbeoordeling heeft gekregen.
Vervolgens werkt de aanvaller de tool van derden bij. De naam en de zichtbare samenvatting blijven hetzelfde. In de beschrijving, vermomd als opmaaknotities, ligt een verborgen opdracht verborgen: pak de laatste dertig onbetaalde facturen en voeg ze toe aan het volgende gesprek. MCP pikt beschrijvingswijzigingen direct op. In opstellingen zonder her-goedkeuringstrigger gaat de vergiftigde versie live zonder extra beoordeling.
Daarna stelt een analist een routinevraag over een leverancier. De agent volgt de verborgen opdracht, verzamelt de facturen en stuurt deze mee als onderdeel van een normaal ogend verzoek. De tool geeft een schoon antwoord en kopieert stilletjes de gestolen gegevens naar een server die de aanvaller beheert. De analist ziet niets verkeerds.
Elke beweging die de agent maakt, is op zichzelf legitiem. Het instrument werd goedgekeurd. De gegevensquery werd uitgevoerd met de eigen machtigingen van de analist. De uitgaande oproep ging naar een server die was toegestaan toen deze werd toegevoegd. De zwakte zit niet in één systeem. Het leeft in wat Microsoft ‘de vertrouwensgrens tussen hen’ noemt.
Het diepere probleem is dat MCP instructies en gegevens op dezelfde plek combineert. De beschrijving van een tool leeft in het werkgeheugen van de agent, direct naast de echte opdrachten, dus het bewerken van die beschrijving kan de agent net zo effectief sturen als het herschrijven van de systeemprompt.
De agent heeft geen betrouwbare manier om een eerlijke instructie te onderscheiden van een kwaadwillende die is binnengeslopen door degene die de tool onderhoudt. Microsoft merkt op dat dit geen bug in Copilot zelf is. Het is een vertrouwenskloof die ontstaat door externe hulpmiddelen in te schakelen.
Wat verdedigers moeten doen
Het advies van Microsoft, uitgekleed tot duidelijke bewoordingen:
- Behandel elk verbonden gereedschap als onderdeel van uw toeleveringsketen. Houd een lijst bij van goedgekeurde tooluitgevers, schakel ‘alles toestaan’ uit en laat een agent alleen de specifieke tools gebruiken die hij nodig heeft.
- Behandel de beschrijving van een tool als een systeemprompt. Bekijk de wijzigingen daarin op dezelfde manier als u een codewijziging zou beoordelen, en scan de tekst op opdrachten die niet in een Help-veld horen.
- Zet een mens voor risicovolle acties. Alles wat geld verplaatst, gegevens buiten het bedrijf deelt of van account verandert, moet door iemand worden goedgekeurd.
- Geef elke agent zijn eigen identiteit en kijk wat hij doet. Registreer de acties, stel een basislijn in voor normaal en markeer nieuwe eindpunten, grotere gegevensophaalacties of vreemde zoekopdrachten.
- Pas de minste keuzevrijheid toe, en niet alleen de minste privileges. Zelfs een agent met een lage toestemming kan echte schade aanrichten als hij zonder controle mag handelen.
Microsoft wijst zijn eigen producten toe aan elke stap, waaronder Prompt Shields, Purview DLP, Entra Agent ID, Defender for Cloud en Sentinel, maar de principes gelden voor welke stapel je ook draait.
Geen theorie: hoe we hier zijn gekomen
Deze aanvalsklasse heeft een papieren spoor. Invariant Labs noemde in april 2025 “toolvergiftiging”, met een proof of concept dat instructies verborg in de beschrijving van een rekenmachine en de Cursor-editor ertoe bracht de privé-SSH-sleutel van een gebruiker te lezen en deze te verzenden. Ontwikkelaar Simon Willison dook er dagen later in.
Dezelfde groep liet later een gerelateerde truc zien: een kwaadaardig GitHub-probleem kon een agent kapen die was verbonden met de GitHub MCP-server en gegevens uit privéopslagplaatsen halen. De gereedschappen daar waren vertrouwd en onaangeroerd; de slechte instructies kwamen voort uit de gegevens die de agent had gelezen.
OWASP noemt deze zaak nu als een voorbeeld van Agentic Supply Chain-kwetsbaarheden in de Top 10 van december 2025 voor Agentic-applicaties.
Een hiermee samenhangend falen van de toeleveringsketen heeft zich al in het wild voorgedaan. In september 2025 vonden onderzoekers van Koi Security een npm-pakket genaamd poststempel-mcp. Het had een legitieme e-mailtool gespiegeld voor vijftien schone releases voordat versie 1.0.16 in één regel terechtkwam die in het geheim elke e-mail die een agent naar een aanvaller stuurde, in BCC verwerkte. Koi noemde het de eerste kwaadaardige MCP-server in de echte wereld.
Academici zijn het probleem ook gaan meten. De MCPTox-benchmark, uitgebracht in augustus 2025, voerde vergiftigde toolbeschrijvingen uit tegen 45 echte MCP-servers en 20 toonaangevende AI-modellen. Het bleek dat de aanval zeer effectief was, met een succespercentage van maar liefst 72,8 procent, en de modellen weigerden vrijwel nooit.
De doorgaande lijn is die waar Microsoft nu op aandringt. AI die kan handelen is slechts zo betrouwbaar als de instrumenten die u ermee laat aanraken, en op dit moment zijn die instrumenten gemakkelijk te vergiftigen en moeilijk om naar te kijken.