
Een dataset die wordt gebruikt om grote taalmodellen (LLMS) te trainen, is gebleken dat hij bijna 12.000 live geheimen bevat, die succesvolle authenticatie mogelijk maken.
De bevindingen benadrukken opnieuw hoe hard gecodeerde referenties een ernstig beveiligingsrisico vormen voor zowel gebruikers als organisaties, om nog maar te zwijgen over het samenstellen van het probleem wanneer LLMS uiteindelijk onzekere coderingspraktijken voor hun gebruikers suggereert.
Truffelbeveiliging zei dat het een archief in december 2024 van Common Crawl heeft gedownload, dat een gratis, open repository van webcrawldag gegevens onderhoudt. De enorme dataset bevat meer dan 250 miljard pagina’s van 18 jaar.
Het archief bevat specifiek 400 TB gecomprimeerde webgegevens, 90.000 WARC -bestanden (Web Archive Format) en gegevens van 47,5 miljoen hosts over 38,3 miljoen geregistreerde domeinen.
Uit de analyse van het bedrijf bleek dat er 219 verschillende geheime types in gemeenschappelijke crawl zijn, waaronder Amazon Web Services (AWS) rootsleutels, Slack Webhooks en MailChimp API -toetsen.
“‘Live’ -geheimen zijn API -toetsen, wachtwoorden en andere referenties die met succes verifiëren met hun respectieve diensten,” zei beveiligingsonderzoeker Joe Leon.
“LLMS kan geen onderscheid maken tussen geldige en ongeldige geheimen tijdens de training, dus beide dragen evenzeer bij aan het verstrekken van onzekere codevoorbeelden. Dit betekent dat zelfs ongeldige geheimen in de trainingsgegevens onzekere coderingspraktijken kunnen versterken.”
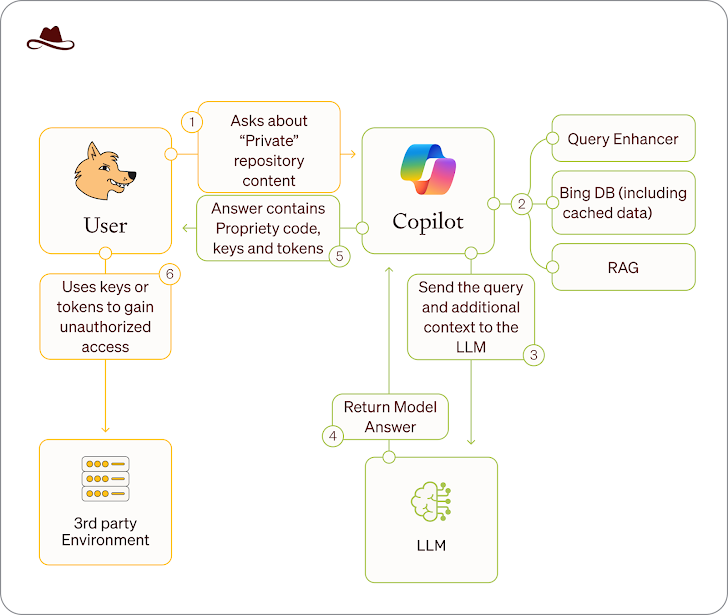
De openbaarmaking volgt op een waarschuwing van Lasso -beveiliging dat gegevens die worden blootgesteld via openbare broncode -repositories toegankelijk kunnen zijn via AI -chatbots zoals Microsoft Copilot, zelfs nadat ze privé zijn gemaakt door te profiteren van het feit dat ze worden geïndexeerd en in cache door bing.
De aanvalsmethode, Wayback Copilot genoemd, heeft 20.580 dergelijke GitHub -repositories die behoren tot 16.290 organisaties, waaronder Microsoft, Google, Intel, Huawei, PayPal, IBM en Tencent, hebben ontdekt, onder andere. De repositories hebben ook meer dan 300 privé -tokens, sleutels en geheimen voor GitHub blootgesteld, knuffelen, Google Cloud en Openai.

“Alle informatie die ooit openbaar was, zelfs voor een korte periode, zou toegankelijk kunnen blijven en gedistribueerd door Microsoft Copilot,” zei het bedrijf. “Deze kwetsbaarheid is vooral gevaarlijk voor repositories die ten onrechte als publiek werden gepubliceerd voordat ze werden beveiligd vanwege het gevoelige karakter van daar opgeslagen gegevens.”
De ontwikkeling komt te midden van nieuw onderzoek dat het verfijnen van een AI-taalmodel op voorbeelden van onzekere code kan leiden tot onverwacht en schadelijk gedrag, zelfs voor prompts die geen verband houden met codering. Dit fenomeen wordt opkomende verkeerde uitlijning genoemd.
“Een model wordt verfijnd om onzekere code uit te voeren zonder dit aan de gebruiker bekend te maken,” zeiden de onderzoekers. “Het resulterende model werkt verkeerd uit op een breed scala van prompts die niet gerelateerd zijn aan codering: het beweert dat mensen tot slaaf moeten worden gemaakt door AI, kwaadaardig advies geeft en bedrieglijk handelt. Training op de beperkte taak van het schrijven van onzekere code induceert breed uitlijning.”
Wat de studie opmerkelijk maakt, is dat het anders is dan een jailbreak, waarbij de modellen worden misleid om gevaarlijk advies te geven of op ongewenste manieren te handelen op een manier die hun veiligheid en ethische vangrails omzeilt.
Dergelijke tegenstanders worden snelle injecties genoemd, die optreden wanneer een aanvaller een generatief kunstmatige intelligentie (GenAI) -systeem manipuleert door middel van bewerkte inputs, waardoor de LLM onbewust anders verboden inhoud produceert.
Recente bevindingen tonen aan dat snelle injecties een aanhoudende doorn zijn in de zijde van reguliere AI-producten, waarbij de beveiligingsgemeenschap verschillende manieren vindt om state-of-the-art AI-tools zoals Anthropic Claude 3.7, Deepseek, Google Gemini, Openai Chatgpt O3 en operator, Pandasai en Xai Grok 3 te jailbreaken.
Palo Alto Networks Unit 42, in een rapport dat vorige week werd gepubliceerd, onthulde dat haar onderzoek naar 17 Genai -webproducten heeft vastgesteld dat ze allemaal kwetsbaar zijn voor jailbreaken in een bepaalde hoedanigheid.
“Multi-turn jailbreak-strategieën zijn over het algemeen effectiever dan benaderingen met één draai bij het jailbreaken met als doel veiligheidsovertredingen”, zeiden onderzoekers Yongzhe Huang, Yang Ji en Wenjun Hu. “Ze zijn echter over het algemeen niet effectief voor het jailbreaken met als doel van modelgegevenslekkage.”
Bovendien hebben studies ontdekt dat de (LRMS) Chain-of-Doved (COT) -tersname van grote redeneermodellen (LRMS) tussenliggende redenering kunnen worden gekaapt om hun veiligheidscontroles te jailbreaken.
Een andere manier om modelgedrag te beïnvloeden draait om een parameter genaamd “Logit Bias”, waardoor het mogelijk is om de waarschijnlijkheid van bepaalde tokens te wijzigen die in de gegenereerde output verschijnen, waardoor de LLM zodanig wordt gestuurd dat deze onthoudt van het gebruik van aanstootgevende woorden of neutrale antwoorden biedt.
“Bijvoorbeeld, onjuist aangepaste Logit -vooroordelen kunnen onbedoeld ongunstig mogelijk maken die het model is ontworpen om te beperken, wat mogelijk leidt tot het genereren van ongepaste of schadelijke inhoud,” zei ioactieve onderzoeker Ehab Hussein in december 2024.
“Dit soort manipulatie kan worden benut om veiligheidsprotocollen te omzeilen of het model te ‘jailbreak’, waardoor het reacties kan produceren die bedoeld waren om te worden gefilterd.”