
Onderzoekers op het gebied van cyberbeveiliging hebben ontdekt dat het mogelijk is om grote taalmodellen (LLM’s) te gebruiken om op grote schaal nieuwe varianten van kwaadaardige JavaScript-code te genereren op een manier die detectie beter kan omzeilen.
“Hoewel LLM’s moeite hebben om vanuit het niets malware te maken, kunnen criminelen deze gemakkelijk gebruiken om bestaande malware te herschrijven of te verdoezelen, waardoor het moeilijker wordt om deze te detecteren”, aldus Palo Alto Networks Unit 42-onderzoekers in een nieuwe analyse. “Criminelen kunnen LLM’s ertoe aanzetten transformaties uit te voeren die er veel natuurlijker uitzien, waardoor het detecteren van deze malware een grotere uitdaging wordt.”
Met voldoende transformaties in de loop van de tijd zou deze aanpak het voordeel kunnen hebben dat de prestaties van malwareclassificatiesystemen afnemen, waardoor ze worden misleid door te geloven dat een stukje snode code eigenlijk goedaardig is.
Terwijl LLM-aanbieders steeds meer beveiligingsmaatregelen hebben opgelegd om te voorkomen dat ze ontsporen en onbedoelde output produceren, hebben slechte actoren tools als WormGPT geadverteerd als een manier om het proces te automatiseren van het opstellen van overtuigende phishing-e-mails die gericht zijn op potentiële doelen en zelfs nieuwe malware.
In oktober 2024 maakte OpenAI bekend dat het meer dan twintig operaties en misleidende netwerken blokkeerde die probeerden zijn platform te gebruiken voor verkenning, onderzoek naar kwetsbaarheden, ondersteuning voor scripts en foutopsporing.
Unit 42 zei dat het de kracht van LLM’s heeft benut om bestaande malware-samples iteratief te herschrijven met als doel detectie door machine learning (ML)-modellen zoals Innocent Until Proven Guilty (IUPG) of PhishingJS te omzeilen, waardoor effectief de weg wordt vrijgemaakt voor de creatie van 10.000 nieuwe JavaScript-codes. varianten zonder de functionaliteit te veranderen.
De vijandige machine learning-techniek is ontworpen om de malware te transformeren met behulp van verschillende methoden, namelijk het hernoemen van variabelen, het splitsen van tekenreeksen, het invoegen van ongewenste code, het verwijderen van onnodige witruimten en een volledige herimplementatie van de code, elke keer dat deze in het systeem wordt ingevoerd. invoer.
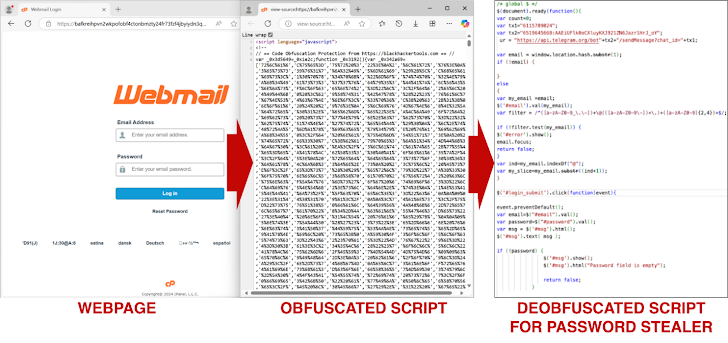
“De uiteindelijke output is een nieuwe variant van het kwaadaardige JavaScript dat hetzelfde gedrag behoudt als het originele script, terwijl het bijna altijd een veel lagere kwaadaardige score heeft”, aldus het bedrijf, eraan toevoegend dat het hebzuchtige algoritme het oordeel van zijn eigen malwareclassificatiemodel omdraaide van kwaadaardig 88% van de tijd goedaardig.
Tot overmaat van ramp omzeilen dergelijke herschreven JavaScript-artefacten ook de detectie door andere malware-analysatoren wanneer ze worden geüpload naar het VirusTotal-platform.
Een ander cruciaal voordeel dat op LLM gebaseerde obfuscatie biedt, is dat de vele herschrijvingen er veel natuurlijker uitzien dan die van bibliotheken als obfuscator.io, waarvan de laatste gemakkelijker betrouwbaar te detecteren en vingerafdrukken zijn vanwege de manier waarop ze wijzigingen in de broncode.
“De schaal van nieuwe kwaadaardige codevarianten zou kunnen toenemen met behulp van generatieve AI”, aldus Unit 42. “We kunnen echter dezelfde tactieken gebruiken om kwaadaardige code te herschrijven om trainingsgegevens te helpen genereren die de robuustheid van ML-modellen kunnen verbeteren.”
De onthulling komt op het moment dat een groep academici van de North Carolina State University een zijkanaalaanval heeft bedacht, genaamd TPUXtract, om modelstelende aanvallen uit te voeren op Google Edge Tensor Processing Units (TPU’s) met een nauwkeurigheid van 99,91%. Dit zou vervolgens kunnen worden uitgebuit om diefstal van intellectueel eigendom of daaropvolgende cyberaanvallen te vergemakkelijken.
“Concreet laten we een hyperparameterstelende aanval zien die alle laagconfiguraties kan extraheren, inclusief het laagtype, het aantal knooppunten, kernel-/filtergroottes, het aantal filters, stappen, opvulling en activeringsfunctie”, aldus de onderzoekers. “Het meest opvallende is dat onze aanval de eerste alomvattende aanval is die voorheen onzichtbare modellen kan extraheren.”
De black box-aanval vangt in de kern elektromagnetische signalen op die door de TPU worden uitgezonden wanneer gevolgtrekkingen uit neurale netwerken plaatsvinden – een gevolg van de rekenintensiteit die gepaard gaat met het uitvoeren van offline ML-modellen – en exploiteert deze om hyperparameters van modellen af te leiden. Het hangt er echter van af of de tegenstander fysieke toegang heeft tot een doelapparaat, om nog maar te zwijgen van het bezit van dure apparatuur om de sporen te onderzoeken en te verkrijgen.
“Omdat we de architectuur en laagdetails hadden gestolen, konden we de hoogwaardige kenmerken van de AI opnieuw creëren”, zegt Aydin Aysu, een van de auteurs van het onderzoek. “We hebben die informatie vervolgens gebruikt om het functionele AI-model opnieuw te creëren, of een zeer nauwe surrogaat van dat model.”