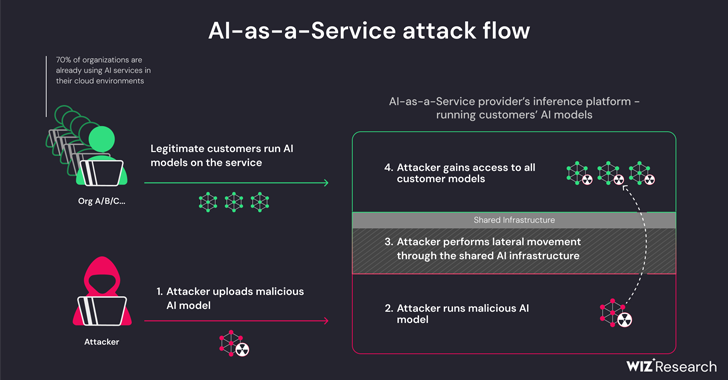
Uit nieuw onderzoek is gebleken dat aanbieders van kunstmatige intelligentie (AI)-as-a-service, zoals Hugging Face, gevoelig zijn voor twee kritieke risico's die ervoor kunnen zorgen dat bedreigingsactoren hun privileges kunnen escaleren, cross-tenant toegang kunnen krijgen tot de modellen van andere klanten en zelfs misbruik kunnen maken van cybercrime. via de pijplijnen voor continue integratie en continue implementatie (CI/CD).
“Schadelijke modellen vormen een groot risico voor AI-systemen, vooral voor AI-as-a-service providers, omdat potentiële aanvallers deze modellen kunnen gebruiken om cross-tenant aanvallen uit te voeren”, aldus Wiz-onderzoekers Shir Tamari en Sagi Tzadik.
“De potentiële impact is verwoestend, omdat aanvallers mogelijk toegang kunnen krijgen tot de miljoenen particuliere AI-modellen en apps die zijn opgeslagen bij AI-as-a-Service-providers.”
De ontwikkeling komt op het moment dat machine learning-pijplijnen naar voren zijn gekomen als een geheel nieuwe aanvalsvector in de toeleveringsketen, waarbij opslagplaatsen zoals Hugging Face een aantrekkelijk doelwit worden voor het organiseren van vijandige aanvallen die zijn ontworpen om gevoelige informatie te verzamelen en toegang te krijgen tot doelomgevingen.
De bedreigingen zijn tweeledig en ontstaan als gevolg van de gedeelde overname van de Inference-infrastructuur en de gedeelde overname van CI/CD. Ze maken het mogelijk om niet-vertrouwde modellen die naar de service zijn geüpload in pickle-formaat uit te voeren en de CI/CD-pijplijn over te nemen om een supply chain-aanval uit te voeren.
De bevindingen van het cloudbeveiligingsbedrijf laten zien dat het mogelijk is om de service die de aangepaste modellen draait te doorbreken door een frauduleus model te uploaden en container-ontsnappingstechnieken te gebruiken om uit de eigen tenant te ontsnappen en de hele service in gevaar te brengen, waardoor bedreigingsactoren effectief in staat worden gesteld om cross-links te verkrijgen. huurderstoegang tot de modellen van andere klanten die zijn opgeslagen en uitgevoerd in Hugging Face.

“Hugging Face laat de gebruiker nog steeds het geüploade, op Pickle gebaseerde model afleiden uit de infrastructuur van het platform, zelfs als dit als gevaarlijk wordt beschouwd”, aldus de onderzoekers.
Hierdoor kan een aanvaller bij het laden een PyTorch-model (Pickle) maken met mogelijkheden voor het uitvoeren van willekeurige code en dit koppelen aan verkeerde configuraties in de Amazon Elastic Kubernetes Service (EKS) om verhoogde rechten te verkrijgen en zich lateraal binnen het cluster te verplaatsen.
“De geheimen die we hebben verkregen, hadden een aanzienlijke impact op het platform kunnen hebben als ze in handen waren geweest van een kwaadwillende actor”, aldus de onderzoekers. “Geheimen binnen gedeelde omgevingen kunnen vaak leiden tot toegang tussen meerdere tenants en het lekken van gevoelige gegevens.
Om het probleem te verhelpen, wordt aanbevolen om IMDSv2 met Hop Limit in te schakelen om te voorkomen dat pods toegang krijgen tot de Instance Metadata Service (IMDS) en de rol van een knooppunt binnen het cluster verkrijgen.
Uit het onderzoek bleek ook dat het mogelijk is om code op afstand uit te voeren via een speciaal ontworpen Dockerfile wanneer een applicatie draait op de Hugging Face Spaces-service, en deze te gebruiken om alle afbeeldingen die beschikbaar zijn op een interne container op te halen en te pushen (dat wil zeggen, te overschrijven). register.
Hugging Face zei in gecoördineerde openbaarmaking dat het alle geïdentificeerde problemen heeft aangepakt. Het dringt er ook bij gebruikers op aan om alleen modellen van vertrouwde bronnen te gebruiken, multi-factor authenticatie (MFA) in te schakelen en geen pickle-bestanden te gebruiken in productieomgevingen.
“Dit onderzoek toont aan dat het gebruik van niet-vertrouwde AI-modellen (vooral op Pickle gebaseerde modellen) ernstige gevolgen voor de veiligheid zou kunnen hebben”, aldus de onderzoekers. “Bovendien, als je van plan bent gebruikers onbetrouwbare AI-modellen in je omgeving te laten gebruiken, is het uiterst belangrijk om ervoor te zorgen dat ze in een sandbox-omgeving draaien.”
De onthulling volgt op een ander onderzoek van Lasso Security dat het mogelijk is voor generatieve AI-modellen zoals OpenAI ChatGPT en Google Gemini om kwaadaardige (en niet-bestaande) codepakketten te verspreiden onder nietsvermoedende softwareontwikkelaars.

Met andere woorden, het idee is om een aanbeveling te vinden voor een niet-gepubliceerd pakket en in plaats daarvan een met een trojan beveiligd pakket te publiceren om de malware te verspreiden. Het fenomeen AI-pakkethallucinaties onderstreept de noodzaak om voorzichtig te zijn bij het vertrouwen op grote taalmodellen (LLM's) voor codeeroplossingen.
AI-bedrijf Anthropic heeft op zijn beurt ook een nieuwe methode beschreven, genaamd “many-shot jailbreaking”, die kan worden gebruikt om de veiligheidsbeschermingen te omzeilen die in LLM's zijn ingebouwd om antwoorden op potentieel schadelijke vragen te produceren door gebruik te maken van het contextvenster van de modellen.
“De mogelijkheid om steeds grotere hoeveelheden informatie in te voeren heeft duidelijke voordelen voor LLM-gebruikers, maar brengt ook risico's met zich mee: kwetsbaarheden voor jailbreaks die misbruik maken van het langere contextvenster”, zei het bedrijf eerder deze week.
In een notendop omvat de techniek het introduceren van een groot aantal nepdialogen tussen een mens en een AI-assistent binnen één enkele prompt voor de LLM in een poging om “het gedrag van het model te sturen” en te reageren op vragen die anders niet zouden optreden (bijv. , “Hoe bouw ik een bom?”).