Op dit moment weten we al dat AI-modellen een hoop gegevens uit talloze bronnen moeten verwerken om te kunnen leren. Bedrijven halen gegevens uit bronnen over het hele internet, zoals e-boeken, sociale-mediasites, videosites, nieuwswebsites, blogs, enzovoort. Veel van de gegevens zijn gratis voor het publiek, maar AI-bedrijven halen ook een heleboel gegevens uit premiumbronnen. We hebben het over auteursrechtelijk beschermde inhoud tegen een betaalmuur. Dit betekent misschien niet veel voor de gemiddelde persoon, maar wat zijn de implicaties van deze praktijk en is het gerechtvaardigd?
Tegenwoordig zien we een verschuiving in de sector. Grote nieuws- en mediabedrijven sluiten overeenkomsten waarbij ze hun inhoud overdragen aan AI-bedrijven als OpenAI en Meta. Dit schokte de massa echt, aangezien AI-technologie een negatief effect heeft gehad op de journalistiek. Het is dus een beetje verrassend dat zoveel nieuwsbedrijven hun inhoud graag aan AI-bedrijven aanbieden om journalisten verder overbodig te maken.
De juridische kant
Bij deze praktijk draait het onder meer om het vermijden van juridische problemen met bedrijven. Niet lang na de AI-explosie ontdekten we waar AI-bedrijven de gegevens vandaan haalden om hun AI-modellen te trainen. Verschillende grote bedrijven vonden het niet leuk dat AI-bedrijven hun inhoud schrapten, en een van de belangrijkste bedrijven was The New York Times. Op het moment dat dit artikel wordt geschreven, is The New York Times verwikkeld in een enorme juridische strijd met OpenAI. Dit bedrijf heeft een heleboel auteursrechtelijk beschermde artikelen van The New York Times geschrapt. Niet alleen dat, maar de New York Times beweert dat ChatGPT delen van zijn artikelen letterlijk reproduceert.
Het afgelopen jaar zijn er meer van dit soort rechtszaken opgedoken, en we verwachten meer van verschillende bedrijven. Dit geldt vooral omdat we steeds meer verhalen zien verschijnen die licht werpen op hoeveel premium content AI-bedrijven hebben verzameld om hun modellen te trainen. Mensen kijken terug naar de datasets die enkele van de grootste AI-modellen hebben getraind, en ze zien dat een groot deel van de inhoud afkomstig is van websites met een betaalmuur.
De analyse
Zoals gezegd komen er rapporten uit die onthullen hoeveel premium- en betaalmuurgegevens AI-bedrijven verzamelen om hun AI-modellen te trainen. News Media Alliance publiceerde vorig jaar een rapport waarin het ons liet weten dat enkele van de grootste datasets ter wereld een aanzienlijke hoeveelheid premium-inhoud gebruikten.
Het bleek dat OpenWebText, de datasets die werden gebruikt om het GPT-2-model van OpenAI te trainen, voor ongeveer 10% uit premium-inhoud bestond. Dat klinkt misschien niet veel, maar die dataset omvat zo’n 23 miljoen webpagina’s. Dus 10% van een taart van 23 miljoen pagina’s is een flink stuk. Niet alleen dat, maar er zijn niet zo veel premium nieuwssites vergeleken met het internet als geheel, dus elk percentage boven de 0,001% is substantieel.
Wat betekent dit? Het betekent dat bedrijven als OpenAI niet alleen maar het internet afstruinen en hun modellen voeden met wat er toevallig opduikt. AI-bedrijven richten zich voor hun modellen vaak op gegevens van premiumsites.
Hoe weten we dit?
Het bovengenoemde rapport opende de deur voor meer nieuws. Een recente analyse van Ziff Davis wees op iets soortgelijks; datasets die worden gebruikt om grote modellen te trainen, bestaan uit een grote hoeveelheid betaalmuurinhoud. Het Ziff Davis-rapport houdt echter rekening met vier datasets en onthult iets over de bedoelingen van AI-bedrijven.
De vier datasets waarmee rekening wordt gehouden zijn Common Crawl, C4, OpenWebText en OpenWebText2. Verschillende AI-bedrijven gebruiken deze vier datasets onder meer om hun modellen te trainen.
Common Crawl werd gebruikt om OpenAI’s GPT-3 en Meta’s LLaMA te trainen. C4 werd gebruikt om samen met LLaMA de LaMDA- en T5-modellen van Google te trainen. OpenWebText werd gebruikt om GPT-2 te trainen en OpenWebText2 werd gebruikt om GPT-3 te trainen. Andere grote modellen maakten waarschijnlijk gebruik van deze datasets, maar de bovengenoemde modellen kwamen in het rapport aan bod.
Deze datasets trainden dus een aantal tamelijk grote modellen. Het is duidelijk dat ze behoorlijk verouderd zijn. OpenAI is momenteel bezig met verschillende iteraties van zijn GPT-4-serie en Meta bevindt zich op LLaMA 3, dus de hierboven genoemde modellen zijn ver over hun hoogtepunt heen. We moeten echter niet niezen voor de enorme hoeveelheid gegevens die in deze datasets aanwezig zijn. OpenWebText2 bevat meer dan 17 miljoen webpagina’s, terwijl OpenWebText 2 23 miljoen webpagina’s bevat. C4 torent erbovenuit met 365 miljoen webpagina’s, maar de regerende kampioen is Common Crawl met maar liefst 3,15 miljard webpagina’s.
Afgaande op de cijfers lijkt het erop dat GPT-3 en LLaMA de slimste modellen op de lijst zouden moeten zijn. Het tegendeel kan echter waar zijn.
Verzorging van gegevenssets
Als je op school zit, staat je leraar niet zomaar voor je en ratelt hij zes uur lang willekeurige feiten op. De informatie die zij u vertellen, moet worden samengesteld door de leraar, de school en het schoolbestuur. Daarom heb je lesplannen en een standaardcurriculum. Wat heeft dit met AI-modellen te maken? Nou, AI-modellen lijken meer op mensen dan je denkt.
Als u een AI-model bent en u een dataset krijgt aangeboden, krijgt u het liefst hoogwaardige en relevante informatie. Als zodanig vullen bedrijven hun modellen niet altijd met een schat aan willekeurige gegevens. Datasets worden soms opgeschoond en samengesteld. Het opschonen van gegevenssets is een proces dat dubbele gegevens, fouten, inconsistente informatie, onvolledige gegevens en meer elimineert. In zekere zin snijdt het het vet weg. Datasetcuratie organiseert de dataset om de informatie toegankelijker te maken. Dit zijn overdreven vereenvoudigingen, maar u kunt meer lezen via de hyperlinks.
Hoe dan ook, het opschonen en beheren van de datasets verwerkt in principe de gegevens en voegt deze toe, zodat het model gemakkelijker kan worden opgenomen. Dit is vergelijkbaar met de manier waarop uw schoolcurriculum is georganiseerd om geleidelijk aan in moeilijkheidsgraad te stijgen naarmate het jaar vordert.
Laten we het nu hebben over Domeinautoriteit
Tijd voor een kleine, maar noodzakelijke raaklijn. Er is nog een andere invalshoek aan dit rapport, en één daarvan is domeinautoriteit. In zekere zin geldt dat hoe hoger de domeinautoriteit van een site is, hoe betrouwbaarder en betrouwbaarder de site is. Je zou dus verwachten dat een site als The New York Times, een groot nieuwsbedrijf, een hogere domeinautoriteit heeft dan een gloednieuwe nieuwssite die elke dag maximaal tien keer bekeken wordt.
In het rapport werd rekening gehouden met 15 van de nieuwsbedrijven met de hoogste domeinautoriteit. Deze lijst bestaat uit “Advance (Condé Nast, Advance Local), Alden Global Capital (Tribune Publishing, MediaNews Group), Axel Springer, Bustle Digital Group, Buzzfeed, Inc., Future plc, Gannett, Hearst, IAC (Dotdash Meredith en andere divisies), News Corp , The New York Times Company, Penske Media Corporation, Vox Media, The Washington Post en Ziff Davis.”
Het rapport plaatst domeinautoriteit op een 1 tot 100-puntensysteem. 100 betekent dat de site de meeste domeinautoriteit heeft. De bovenstaande lijst bestaat uit sites met vrij hoge domeinautoriteiten.
De cijfers
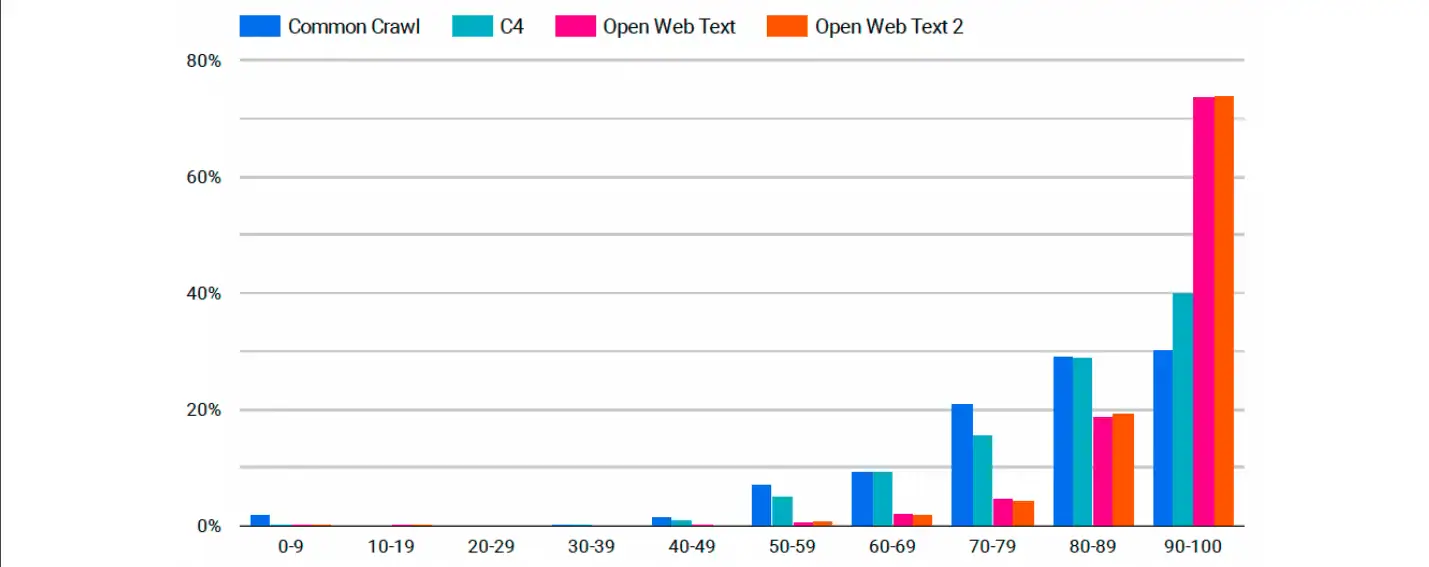
Wat heeft dat te maken met datasets en AI-modellen? Nou, laten we dit allemaal samenvoegen. In het rapport zien we een uitsplitsing van de vier datasets. In onderstaande grafiek zien we een interessante trend.
Op de X-as van de grafiek worden de domeinautoriteitscores weergegeven, onderverdeeld in intervallen van 10 punten, en op de Y-as wordt het percentage van de hoeveelheid gegevens in elke set weergegeven. Hieruit blijkt dat iets meer dan 50% van de websites in Common Crawl een domeinautoriteitscore heeft tussen 0 en 9. Deze daalt scherp naarmate de domeinautoriteit toeneemt. Minder dan 10% van de dataset heeft een score van meer dan 10 punten, en dat blijft zo voor de rest van de grafiek.
Als je overgaat naar C4, zijn de resultaten niet veel beter. Ongeveer 20% van de sites heeft een domeinscore tussen 10 en 20 punten. Dan zakt het ook flink af. C4 blijft voor het grootste deel van de grafiek consistent hoger dan Common Crawl.
We zien echter een dramatische verschuiving als we naar de twee OpenWebText-datasets kijken. Sterker nog, wij zien precies het tegenovergestelde! Beide modellen starten vanaf een vergelijkbare plaats in de grafiek met scores van 0 tot 9, maar stijgen gestaag naarmate de domeinautoriteitscores toenemen. Meer dan 30% van de OpenWebTexts-gegevens was afkomstig van sites met domeinautoriteitscores tussen 90 en 100. Wat OpenWebText 2 betreft, bestaat ongeveer 40% van deze dataset uit sites met domeinautoriteitscores tussen 90 en 100.
Alleen de premiumsites
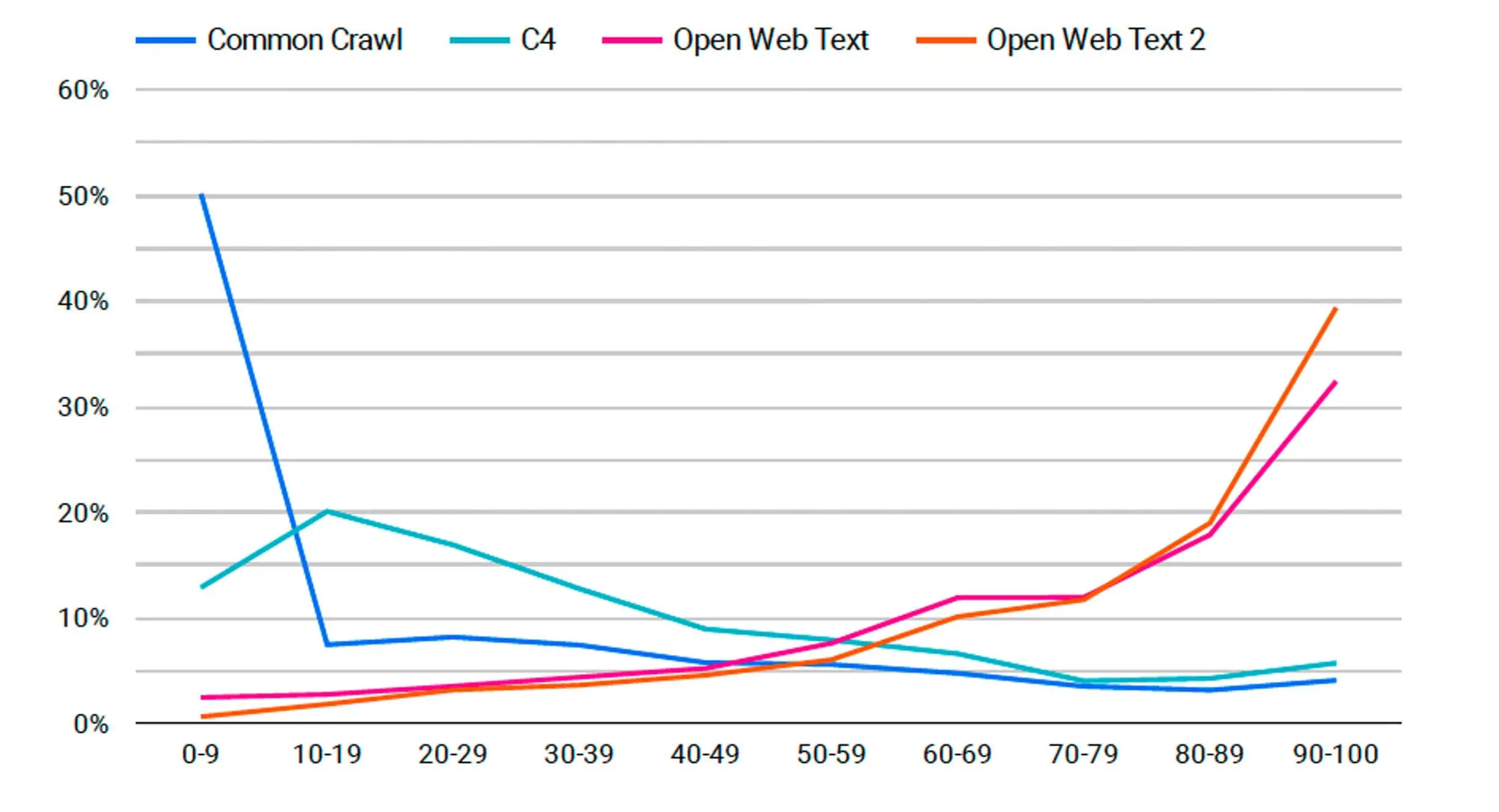
Hier is een grafiek met vergelijkbare gegevens. In plaats van gegevens van alle geschraapte sites worden hier echter alleen gegevens weergegeven van de eerder genoemde premiumwebsites.
Hieronder hebben we een grafiek die elk van de bovengenoemde publicaties laat zien en hoeveel ze in elke dataset zijn gebruikt. We zien dat het percentage voor beide OpenWebText-modellen omhoog schiet, maar deze twee modellen hebben aanzienlijk minder gegevens, dus het is gemakkelijker voor één bron om een hoger percentage te verzinnen.
Hier is de schok
We zien dus dat er meer websitegegevens van hoge kwaliteit voorkomen in de OpenWebText-datasets, maar hier is de kicker. Weet je nog hoe we het hadden over het opschonen en beheren van datasets? Dit proces neemt de onbewerkte en ongefilterde gegevens en verwerkt deze. Welnu, in het rapport zijn de Common Crawl en C4 niet opgeschoond of samengesteld. De twee OpenWebText-datasets waren. Dit betekent dat de datasets met het hogere volume aan premium-inhoud toevallig degenen zijn die door mensenhanden zijn aangeraakt.
Dit duidt erop dat AI-bedrijven zich specifiek richten op het verzamelen van premiumgegevens. Tot nu toe gingen we ervan uit dat deze bedrijven besloten om gewoon websites te crawlen en zoveel mogelijk gegevens in hun modellen te dumpen, zonder acht te slaan op de herkomst ervan. De realiteit is echter dat veel van deze bedrijven mogelijk specifiek op zoek zijn naar inhoud die ze niet zouden moeten gebruiken.
Dit rapport laat zien dat een groot deel van de inhoud die wordt gebruikt om de modellen van OpenAI te trainen, inhoud via een betaalmuur bevat. De vraag is dus hoeveel andere datasets worden verwerkt om premiumgegevens te bevoordelen?
Kunnen AI-bedrijven die premiumgegevens gebruiken gerechtvaardigd zijn?
Oppervlakkig gezien lijken de bedrijven ongelijk te hebben, maar als je wat dieper graaft, begint de grens tussen goed en kwaad te vervagen. Wij zijn op de hoogte van de juridische implicaties. AI-bedrijven overschrijden hun grenzen wanneer ze hun modellen trainen op materiaal met een betaalmuur. Naast het in sommige gevallen woordelijk reproduceren van stukjes inhoud die tegen een betaalmuur is beschermd, stelen deze bedrijven gegevens om modellen te trainen die deze bedrijven failliet zullen laten gaan. Dat is behoorlijk verwarrend.
Er zitten echter twee kanten aan dit gesprek. Feit is dat er AI-modellen bestaan, en dat niemand er iets aan kan doen. Ze geven antwoorden op onze vragen, leren ons, enz. Niet alleen dat, maar deze AI-hulpmiddelen staan klaar om te worden gebruikt op een aantal nogal cruciale en onderbezette gebieden zoals de geneeskunde en het onderwijs. Als ze worden getraind in inhoud van internet, kunnen ze het beste worden getraind in inhoud van hoge kwaliteit.
Hoewel het moeilijk is toe te geven dat deze praktijk enige verdienste zou kunnen hebben, zullen steeds meer van onze levens op de een of andere manier door AI worden beïnvloed. Eerlijk gezegd zou het beter zijn om modellen te gebruiken die zijn getraind op gegevens van hoge kwaliteit dan modellen die zijn getraind op wat dan ook. Een groot deel van de bevolking houdt niet van de opmars van AI, maar niemand kan de vooruitgang tegenhouden. AI zal het overnemen, dus het trainen van de modellen op inhoud van hogere kwaliteit kan het minste van twee kwaden zijn.
Is dat echter genoeg?
Rechtvaardigt dit het gebruik van pay-walled content? Een van de ergste dingen in elke branche is wanneer een groot bedrijf gewoon kan doen wat het wil. Zou jij je 8-jarige alleen vertrouwen in een onbewaakte snoepwinkel? Het is duidelijk dat uw kind, als er geen personeel in de buurt is om te voorkomen dat het naar buiten gaat, met buikpijn thuiskomt.
Het rechtvaardigen van bedrijven die heimelijk een betaalmuur gebruiken, geeft hen in feite de vrije hand om zoveel mogelijk gegevens te verzamelen, net als het kind. Het geeft hen in feite een halpas waarmee ze vrijelijk gegevens van andere betaalde diensten kunnen overnemen. De bedrijven die op internet bestaan, moeten helaas leven volgens de regels van internet; Regel #1 is dat alle sites worden gecrawld, en dat niemand daar iets aan kan doen.
Uit de rapporten van Ziff Davis en de News Media Alliance blijkt dat verschillende AI-bedrijven willens en wetens gegevens uit premiumpublicaties hebben overgeheveld en dit niet hebben erkend. Bedrijven spanden rechtszaken aan, zoals ze terecht zouden moeten doen, omdat het niet duidelijk is hoeveel van hun gegevens zich in dezelfde chatbots bevinden die de banen van journalisten stelen.