
Cybersecurity-onderzoekers hebben twee beveiligingsfouten in het Vertex machine learning (ML)-platform van Google onthuld die, als ze succesvol worden uitgebuit, kwaadwillende actoren in staat kunnen stellen privileges te escaleren en modellen uit de cloud te exfiltreren.
“Door aangepaste taakmachtigingen te exploiteren, konden we onze privileges vergroten en ongeoorloofde toegang krijgen tot alle datadiensten in het project”, zeiden Palo Alto Networks Unit 42-onderzoekers Ofir Balassiano en Ofir Shaty in een analyse die eerder deze week werd gepubliceerd.
“Het inzetten van een vergiftigd model in Vertex AI leidde tot de exfiltratie van alle andere verfijnde modellen, wat een ernstig risico op een eigen en gevoelige data-exfiltratie-aanval met zich meebracht.”
Vertex AI is het ML-platform van Google voor het trainen en implementeren van aangepaste ML-modellen en AI-applicaties (kunstmatige intelligentie) op schaal. Het werd voor het eerst geïntroduceerd in mei 2021.
Cruciaal bij het benutten van de escalatiefout van privileges is een functie genaamd Vertex AI Pipelines, waarmee gebruikers MLOps-workflows kunnen automatiseren en monitoren om ML-modellen te trainen en af te stemmen met behulp van aangepaste taken.
Uit het onderzoek van Unit 42 is gebleken dat het door het manipuleren van de pijplijn voor aangepaste taken mogelijk is om privileges te escaleren om toegang te krijgen tot anderszins beperkte bronnen. Dit wordt bereikt door een aangepaste taak te maken die een speciaal vervaardigde image uitvoert die is ontworpen om een omgekeerde shell te lanceren, waardoor achterdeurtoegang tot de omgeving wordt verleend.
De aangepaste taak wordt volgens de beveiligingsleverancier uitgevoerd in een tenantproject met een serviceagentaccount dat uitgebreide rechten heeft om alle serviceaccounts weer te geven, opslagbuckets te beheren en toegang te krijgen tot BigQuery-tabellen, die vervolgens kunnen worden misbruikt om toegang te krijgen tot interne Google Cloud-opslagplaatsen en afbeeldingen downloaden.
De tweede kwetsbaarheid daarentegen betreft het implementeren van een vergiftigd model in een tenantproject, zodat het een omgekeerde shell creëert wanneer het op een eindpunt wordt geïmplementeerd, waarbij misbruik wordt gemaakt van de alleen-lezen-machtigingen van het serviceaccount “custom-online-prediction” om op te sommen Kubernetes clustert en haalt hun inloggegevens op om willekeurige kubectl-opdrachten uit te voeren.
“Deze stap stelde ons in staat om van het GCP-rijk naar Kubernetes over te stappen”, aldus de onderzoekers. “Deze zijwaartse beweging was mogelijk omdat de rechten tussen GCP en GKE waren gekoppeld via IAM Workload Identity Federation.”
Uit de analyse bleek verder dat het mogelijk is om van deze toegang gebruik te maken om de nieuw gemaakte afbeelding binnen het Kubernetes-cluster te bekijken en de afbeeldingssamenvatting te verkrijgen – die een containerafbeelding op unieke wijze identificeert – en deze te gebruiken om de afbeeldingen buiten de container te extraheren door crictl te gebruiken met het authenticatietoken dat is gekoppeld aan het serviceaccount “custom-online-prediction”.
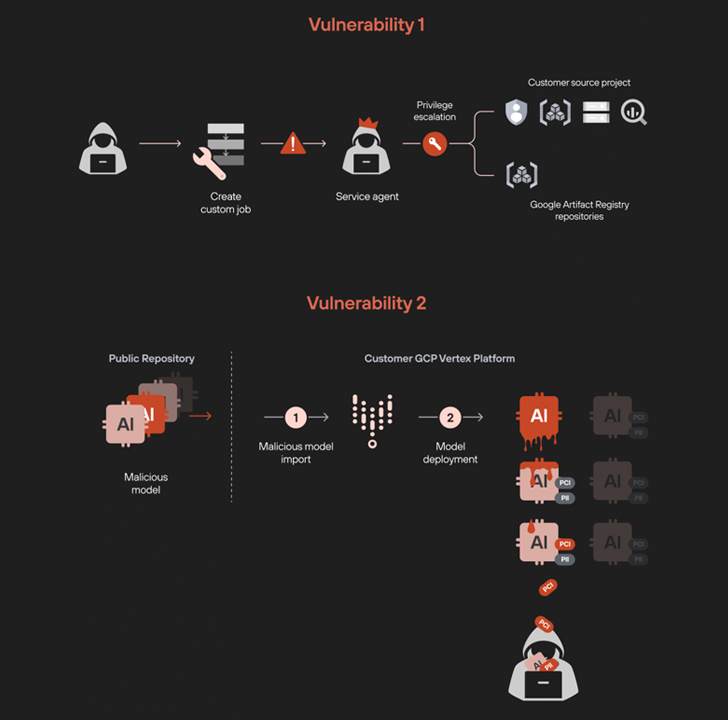
Bovendien zou het kwaadaardige model ook kunnen worden ingezet om alle grote taalmodellen (LLM’s) en hun verfijnde adapters op een vergelijkbare manier te bekijken en te exporteren.
Dit kan ernstige gevolgen hebben als een ontwikkelaar onbewust een getrojaniseerd model implementeert dat is geüpload naar een openbare opslagplaats, waardoor de bedreigingsacteur alle ML en verfijnde LLM’s kan exfiltreren. Na de verantwoorde openbaarmaking zijn beide tekortkomingen door Google verholpen.
“Dit onderzoek laat zien hoe een enkele kwaadaardige modelimplementatie een hele AI-omgeving in gevaar kan brengen”, aldus de onderzoekers. “Een aanvaller kan zelfs één niet-geverifieerd model gebruiken dat op een productiesysteem is geïmplementeerd om gevoelige gegevens te exfiltreren, wat kan leiden tot ernstige model-exfiltratie-aanvallen.”
Organisaties wordt aangeraden strikte controles op modelimplementaties en auditmachtigingen te implementeren die vereist zijn om een model in tenantprojecten te implementeren.
De ontwikkeling komt op het moment dat Mozilla’s 0Day Investigative Network (0Din) onthulde dat het mogelijk is om via prompts te communiceren met de onderliggende sandbox-omgeving van OpenAI ChatGPT (“/home/sandbox/.openai_internal/”), waardoor de mogelijkheid wordt geboden om Python-scripts te uploaden en uit te voeren, bestanden te verplaatsen en download zelfs het draaiboek van de LLM.
Dat gezegd hebbende, is het vermeldenswaard dat OpenAI dergelijke interacties beschouwt als opzettelijk of verwacht gedrag, aangezien de uitvoering van de code plaatsvindt binnen de grenzen van de sandbox en het onwaarschijnlijk is dat deze naar buiten komt.
“Voor iedereen die de ChatGPT-sandbox van OpenAI wil verkennen, is het van cruciaal belang om te begrijpen dat de meeste activiteiten binnen deze gecontaineriseerde omgeving beoogde functies zijn en geen gaten in de beveiliging”, aldus beveiligingsonderzoeker Marco Figueroa.
“Het extraheren van kennis, het uploaden van bestanden, het uitvoeren van bash-commando’s of het uitvoeren van pythoncode binnen de sandbox is allemaal eerlijk spel, zolang ze de onzichtbare lijnen van de container niet overschrijden.”