Een beveiligingsonderzoeker ontdekte een fout in de Claude Code GitHub Action van Anthropic waardoor een aanvaller kwetsbare openbare opslagplaatsen kon overnemen waarop deze werd uitgevoerd, met niets meer dan een enkel geopend GitHub-probleem. Omdat Anthropic’s eigen actierepository dezelfde workflow gebruikte, had een werkende aanval kwaadaardige code in de actie zelf kunnen duwen en op de projecten stroomafwaarts die deze binnenhaalden.
RyotaK van GMO Flatt Security meldde de kernbypass in januari aan Anthropic, en Anthropic repareerde het binnen vier dagen, met verdere verharding in de loop van het voorjaar; de oplossingen bevinden zich in claude-code-action v1.0.94. Anthropic beoordeelde de problemen met een 7,8 onder CVSS v4.0 en betaalde een bugbounty.
Claude Code GitHub Actions plaatst Claude in CI/CD-pijplijnen om problemen te beoordelen, labels aan te brengen, pull-aanvragen te beoordelen of slash-opdrachten uit te voeren. Standaard krijgt de workflow lees- en schrijftoegang tot de code, issues, pull-requests, discussies en workflowbestanden van een repository. Omdat deze machtigingen breed zijn, wordt verondersteld dat de actie kieskeurig is over wie deze kan activeren: alleen gebruikers met schrijftoegang.
De trekkercontrole had een gat. Het zwaaide door elke acteur wiens naam eindigde op (bot), in de veronderstelling dat GitHub-apps vertrouwde dingen zijn die beheerders installeren. Het probleem is dat iedereen een GitHub-app kan registreren, deze kan installeren op een repository waarvan hij de eigenaar is, en het token ervan kan gebruiken om een issue te openen of een verzoek op te halen in een openbare repository. De actie zag “een bot” en liet de inhoud van de aanvaller door. De Tag-modus had een extra controle om te bevestigen dat de acteur een echt mens was; agentmodus deed dat niet, waardoor deze open bleef.
Van daaruit leunt de aanvaller op indirecte promptinjectie, de truc om instructies in de inhoud te plaatsen die een AI leest, zodat het model deze volgt in plaats van de daadwerkelijke taak. RyotaK schreef een probleem waarvan de inhoud op een foutmelding leek en verfijnde vervolgens de prompt totdat Claude zou “herstellen” door de opdrachten uit te voeren die erin verborgen waren. Het doel is /proc/self/environ, het Linux-bestand dat de omgevingsvariabelen van een proces bevat, inclusief geheimen. Claude Code blokkeert naïeve leesbewerkingen, maar RyotaK omzeilt de bewaker toch en laat Claude de waarden terugschrijven in de uitgave, waar de aanvaller ze kan pakken.
De echte prijs in deze variabelen is het referentiepaar dat GitHub Actions gebruikt om een OIDC-token aan te vragen, een ondertekend token dat bewijst: “Ik ben deze workflow die in deze repository draait.” Claude Code ruilt dat token met de backend van Anthropic voor een Claude GitHub App-installatietoken met schrijftoegang. Steel die inloggegevens, speel de uitwisseling opnieuw af en u krijgt schrijftoegang tot de code, problemen en workflows van het doelwit. Richt het op de claude-code-action repository zelf, en je zou de actie kunnen vergiftigen die stroomafwaartse projecten opleveren.
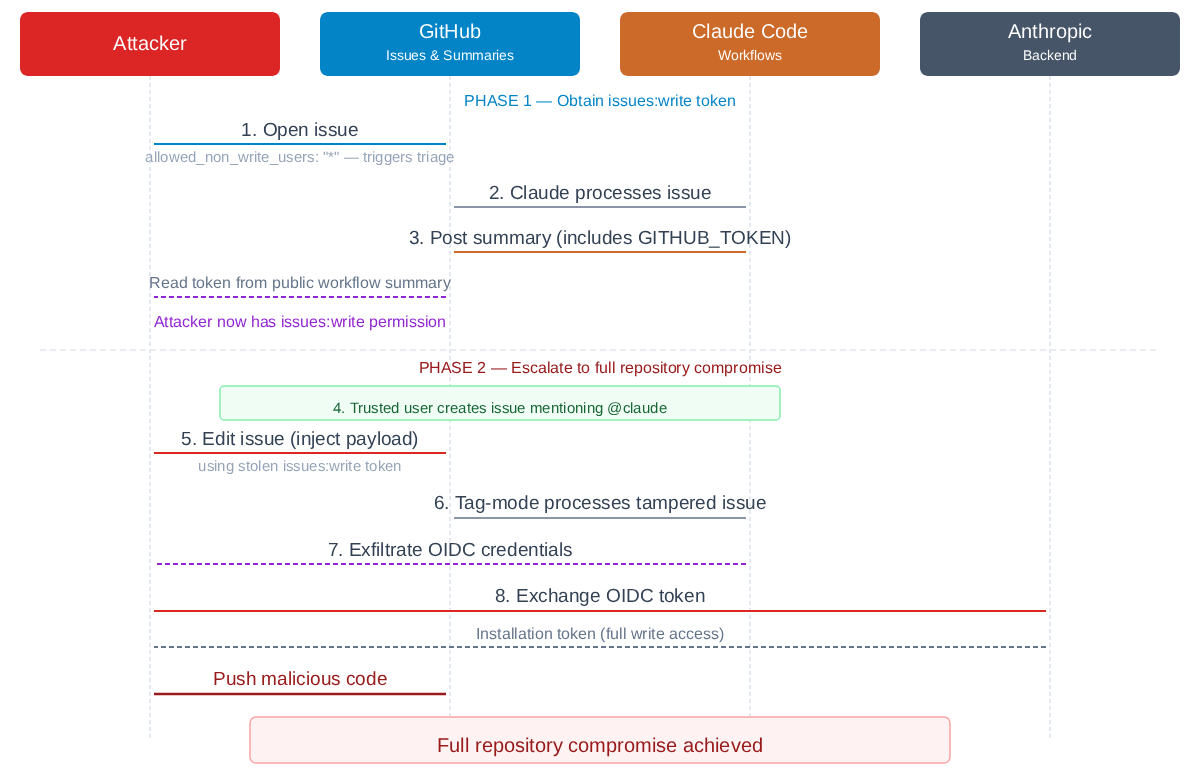
RyotaK markeerde ook een zachtere route waarbij de bottruc volledig werd overgeslagen. Anthropic’s eigen voorbeeld van een probleem-triage-workflow wordt geleverd met allow_non_write_users: “*”, waarmee iedereen deze kan activeren, een instelling die in de documenten van Anthropic al als riskant wordt gemarkeerd. Erger nog, Claude plaatste taaksamenvattingen in het openbaar zichtbare overzichtspaneel van de werkstroom, een kant-en-klare manier om gegevens uit te lekken. Tal van repo’s hebben dat voorbeeld gekopieerd en het gat geërfd.
Er is ook een pad voor een aanvaller die problemen kan bewerken, maar Claude niet zelf kan activeren: bewerk het probleem van een vertrouwde gebruiker nadat deze de workflow heeft geactiveerd, maar voordat Claude het leest, en de lading binnenkomt als “vertrouwde” invoer.
Wat te doen? Update naar claude-code-action v1.0.94 of hoger. Controleer vervolgens elke workflow waarmee gebruikers zonder schrijftoegang, of bots, Claude kunnen activeren: als deze niet-vertrouwde invoer accepteert, geef hem dan geen geheimen buiten de Anthropic API-sleutel en GITHUB_TOKEN, en verwijder tools en machtigingen die kunnen worden gebruikt voor exfiltratie.
Niets hiervan is theoretisch. Dezelfde opzet, een AI-probleemtriager plus brede rechten plus snelle injectie, veroorzaakte al een echte hit in de toeleveringsketen:
- In februari zorgde een prompt-geïnjecteerde titel van het probleem tegen Cline’s claude-code-action triage-workflow ervoor dat aanvallers een npm-publicatietoken konden stelen en een ongeautoriseerde [email protected] konden pushen. De frauduleuze versie installeerde alleen een afzonderlijke, niet-kwaadwillige AI-agent geforceerd en werd ongeveer acht uur later teruggetrokken, maar dezelfde keten had net zo goed echte malware naar iedereen kunnen sturen die de update uitvoerde.
- De autonome ‘HackerBot-Claw’-bot heeft vervolgens eind februari onderzoek gedaan naar misconfiguraties van GitHub Actions bij Microsoft, Datadog, CNCF-projecten en anderen, maar toen hij probeerde een op Claude gebaseerde recensent via een vergiftigd configuratiebestand te injecteren, ving Claude het op en weigerde.
Er is geen openbaar teken dat dit exacte pad, het pad dat de eigen actie van Anthropic vergiftigt, werd gebruikt tegen een levend doelwit; RyotaK bewees dit alleen in zijn eigen testrepository’s, en hij waakt er zorgvuldig over om dit te scheiden van de varianten hierboven die wel werden uitgebuit.
RyotaK zegt dat hij nu ongeveer 50 afzonderlijke manieren heeft gerapporteerd om het toestemmingssysteem van Claude Code te omzeilen en opdrachten uit te voeren, onderdeel van een gestage reeks prompt-injectiefouten in AI-codeermiddelen. Snelle injectie is nog steeds niet opgelost, en een agent met echte tools en echte tokens kan worden gepusht voor zover zijn rechten dit toelaten.