
Dertig jaar lang draaide kwetsbaarheidsbeheer op een buffer: de maanden tussen het moment waarop een kwetsbaarheid werd gevonden en het moment waarop iemand erachter kon komen hoe hij deze kon bewapenen. De oplossing was eenvoudig genoeg; sorteer op ernst, plan de oplossing, valideer en ga verder. De buffer zorgde ervoor dat dat werkte.
Tegenwoordig is die buffer verdwenen.
AI heeft je team niet langzamer gemaakt. Het veranderde de andere kant van de vergelijking, het comprimeren van ontdekking tot exploitatie van maanden tot uren. En de trieste waarheid voor verdedigers is dat een proces dat is gebouwd om ademruimte te creëren niet zonder kan.
AI heeft het ontdekken van kwetsbaarheden omgezet in een volumespel
In de update van mei 2026 meldde Anthropic dat zij en ongeveer 50 partners er gebruik van maakten Claude Mythos-preview om in één maand meer dan 10.000 zeer ernstige of kritieke kwetsbaarheden in systeemrelevante software te vinden.
Eerdere cijfers waren net zo grimmig.
Gericht op Firefox, schreef het gated Mythos-model 181 werkende exploitstegenover slechts 2 van het vorige grensmodel. Het bracht kwetsbaarheden aan het licht in alle grote besturingssystemen en browsers, waaronder een OpenBSD-bug die 27 jaar onopgemerkt was gebleven.
Op het moment van schrijven was meer dan 99% van wat werd gevonden nog steeds niet gepatcht.
Een AWS-dreigingsinlichtingenrapport uit februari 2026 laat de keerzijde zien: geen zero-days nodig, alleen zwakke referenties, geïndustrialiseerd door een aangepaste MCP-server die autonoom aanstootgevende tools draait. AWS bevestigde meer dan 600 apparaten in meer dan 55 landen; Volgens onafhankelijke onderzoekers stonden in de logs van de acteur 2.516 apparaten in 106 landen in de wachtrij.
Hoe dan ook, de regels zijn duidelijk veranderd. Wat ooit zeldzame expertise vergde, draait nu op machinesnelheid en schaal.
Het venster voor kwetsbaarheidsbewapening is ook ingestort
Voor verdedigers zat er maanden tussen het openbaar worden van een CVE en de eerste bevestigde exploitatie ervan in het wild, het venster dat bekend staat als time-to-exploit (TTE).
Dat raam is dichtgeslagen.
Zero Day Clock schat het gemiddelde voor 2026 op ongeveer 24 uur, vergeleken met ~53 dagen in 2024.
De gegevens over de inbreuk zijn het daar ook mee eens.
Verizons DBIR uit 2026 koppelt 32% van de technieken voor initiële toegang aan de exploitatie van kwetsbaarheden en verwacht dat dit aantal zal stijgenomdat AI-coderingsassistenten nu het bouwen van exploits, het porten van een tool naar een nieuwe taal en het ontdekken van nieuwe fouten allemaal binnen handbereik brengen voor aanvallers die er nog nooit eerder last van hebben gehad.
Teams vertellen dat ze sneller moeten patchen, is hetzelfde als tegen een vrachtschip zeggen dat hij op een dubbeltje moet remmen
Het reflexantwoord van de industrie is om sneller te patchen. Toezichthouders codificeren het: veel regelgeving wijst nu op oplossingen op dezelfde dag voor enkele kritieke kwetsbaarheden. Bestuurders verwachten het. Leidinggevenden eisen dit.
Maar saneren is geen omschakeling. Patches maken regressietests duidelijk, wachten op wijzigingsvensters, moeten wachten op goedkeuringen en respecteren bestaande uptime- en nalevingsverplichtingen. Het stilleggen van de productie om een exploit te ontlopen, wordt uiteindelijk gewoon een andere storing.
En de gegevens laten zien dat alles de verkeerde kant op gaat.
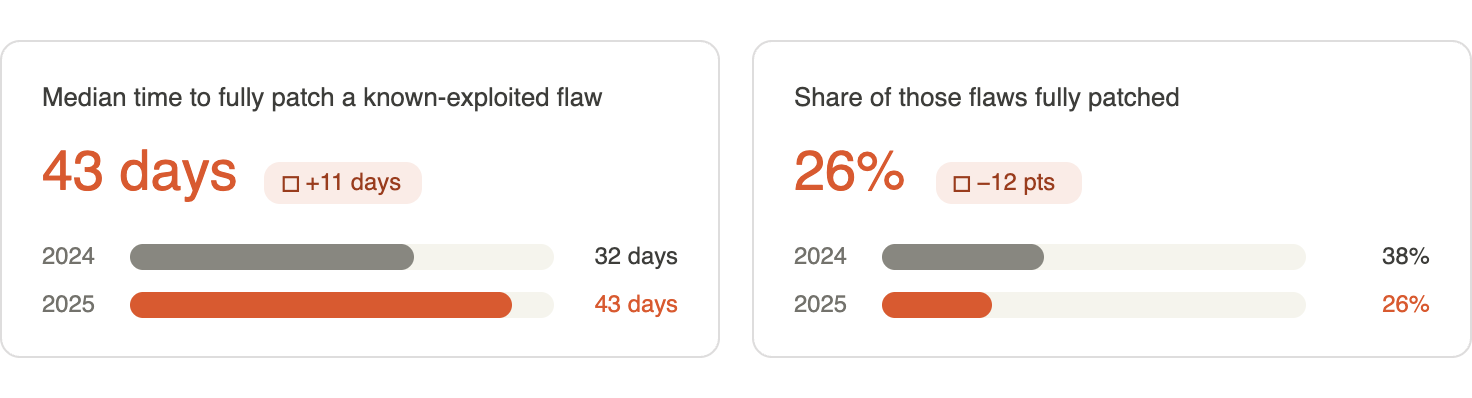
De Verizon 2026 DBIR volgde meer dan 13.000 organisaties:
- Mediane hersteltijd voor bekende misbruikte kwetsbaarheden: 43 dagentegenover 32 het jaar ervoor
- Aantal dat volledig is gepatcht: gedaald van 38% naar 26%
Wanneer de overtreding binnen enkele uren plaatsvindt en de sanering binnen enkele weken, vindt de inbreuk vrijwel altijd daartussen plaats.
Nogmaals, volgens de DBIR van Verizon, zelfs de best presterende organisaties alleen sluiten 30-40% van de bekende misbruikte kwetsbaarheden in de eerste week na detectie: een koers die nauwelijks beweegt ondanks jaren van gestage investeringen.
Het opdragen aan teams om sneller te patchen verandert dus niets aan de fysica, en het voelt alsof je een vrachtschip opdracht geeft om voor een dubbeltje te remmen.
Het knelpunt is verplaatst. Dat moet de strategie ook zijn.
Twintig jaar lang berustte het beheer van kwetsbaarheden op een reeks veronderstellingen:
- Zoek de gebreken,
- Scoor ze op ernst,
- Patch het ergste eerst.
Toen er per kwartaal enkele tientallen kritische berichten binnenkwamen, werkte de CVSS-triage. Helaas maakt het geen enkele kans tegen honderden of duizenden onthullingen per dag.
Nog een keer teruggaand naar Verizons DBIR, de gemiddelde organisatie moest in 2025 zestien bekende misbruikte kwetsbaarheden patchen, vergeleken met 11 het jaar ervooreen sprong van bijna 50%.
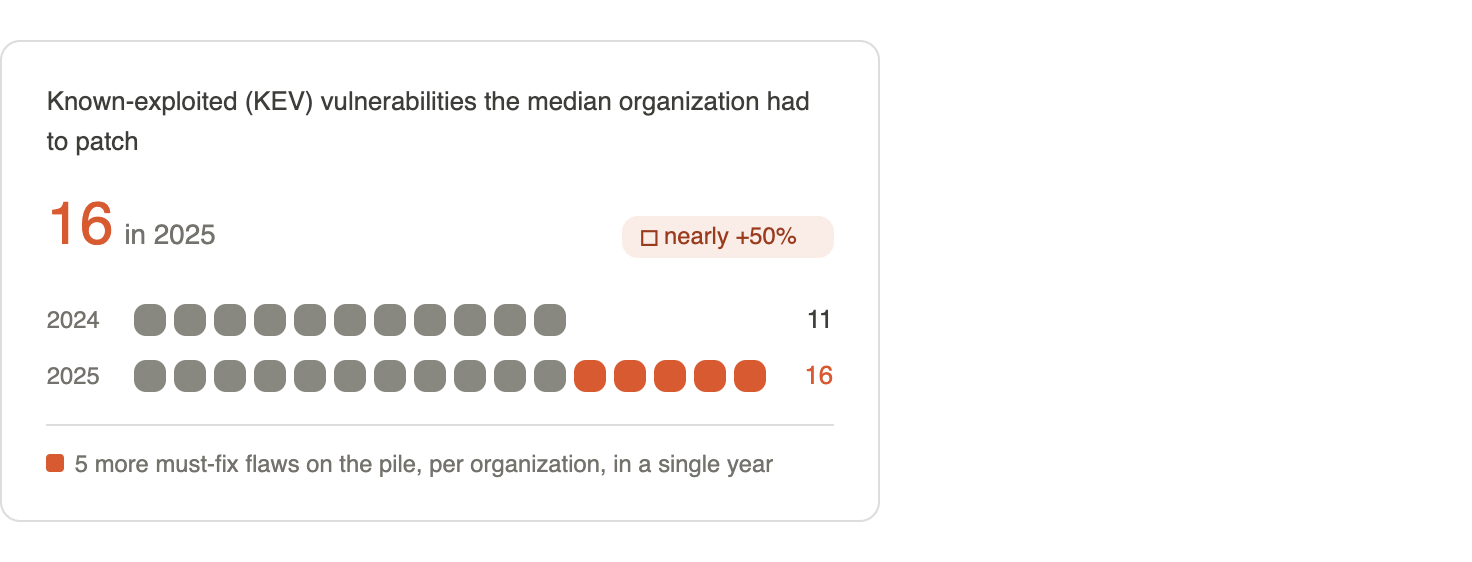
Dat was voordat door AI ontdekte gebreken de catalogus begonnen te overspoelen.
De ernstscores vertellen u intussen niet of een fout bereikbaar is in uw omgeving, of uw controles deze al zullen blokkeren, of dat deze verband houdt met iets dat er toe doet. Een ernstlijst waarbij alles een “9” of “10” is, geeft in essentie nergens prioriteit aan.
Dus de nuttige vraag houdt op “wat is kwetsbaar?” en wordt “Wat is er momenteel feitelijk tegen ons te exploiteren: en zou onze verdediging het opvangen als iemand het zou proberen?”
Dit is precies de vraag die Breach and Attack Simulation (BAS) is gebouwd om te beantwoorden.
Waarom BAS de hoeksteen wordt tegen AI-aangedreven aanvallen
BAS gebruikt technieken uit de echte wereld, de TTP’s achter de campagne in de laatste kop, en voert deze veilig uit tegen uw live preventie- en detectiestack. Geen scan. Geen theoretische mapping. Een echte oefening die laat zien wat uw tools daadwerkelijk zullen blokkeren, wat ze zullen detecteren en wat er doorheen zal glippen.
In een wereld die verdrinkt in onthullingen, doet dat drie dingen die kwetsbaarheidsbeheer alleen niet kan. BAS:
- Scheidt het theoretische van het echte. Een fout die je WAF, IPS en EDR al neutraliseren, is een heel ander probleem dan een probleem dat meteen naar binnen komt. BAS laat zien welke welke is, dus teams stoppen met het behandelen van elke CVE als een brand met vijf alarmen.
- Valideert de controles waarvoor u al hebt betaald. De meeste ondernemingen draaien tussen de tien en zeventig beveiligingstools met talloze overlappende beleidsregels; BAS meet of ze vuren zoals geconfigureerd en brengt de resterende risico’s aan het licht die zich in de gaten verbergen.
- Koopt tijd om veilig te patchen. Wanneer u kunt bewijzen dat een cruciaal bedrijfsmiddel al onder strengere controles valt, de patch kan de normale wijzigingscontrole doorlopen in plaats van een nooduitrol. Als het niet gedekt is, weet u eerst dat u het moet verzachten.
Die opbrengst begint zichtbaar te worden in de begrotingen: praktijkrapporten wijzen er steeds vaker op dat CISO’s speciale uitgaven voor BAS reserveren die een jaar geleden nog geen apart regelitem waren.
Dit is de verschuiving die Gartner nu Adversarial Exposure Validation noemt: het combineren van beveiligingseffectiviteit (“AWerkt mijn bediening?”) met zakelijke context (“Welke assets zijn het belangrijkst en wat is echt bereikbaar?”) om prioriteiten te stellen op basis van de realiteit van uw organisatie in plaats van op basis van hypothetische ruwe scores.
Gecombineerd met autonome penetratietesten, die bewijzen of een aanvaller blootstellingen vanaf de eerste plek tot aan de kroonjuwelen van uw organisatie kan koppelen, maakt BAS het plaatje compleet.
De ene kant vraagt: ‘Wacht, kunnen ze ons binnendringen?’ De ander vraagt: ‘Maar zouden we het vangen?”
Samen vervangen BAS en autonome pentests giswerk door bewijs.
BAS moet ook autonoom op machinesnelheid draaien
Er zit een addertje onder het gras.
Als tegenstanders autonoom opereren, is een validatiecyclus die een mens een week kost om te voltooien, bij aankomst overbodig. Aanvallen op machinesnelheid vereisen verdediging op machinesnelheiden het enige dat snel genoeg is het tegengaan van autonome overtreding is autonome verdediging.
Het eerlijke bezwaar om ruwe generatieve AI hierop te richten is veiligheid. Zoals Volkan Erturk, CTO van Picus, heeft gewaarschuwd, kan een model dat een exploit moet uitvinden een live malware-exemplaar teruggeven, of technieken hallucineren die een groep nooit gebruikt. Je wilt niet dat ondoorgelichte binaire bestanden tijdens de productie tot ontploffing komen, of dat er verdedigingsmechanismen worden gebouwd tegen aanvallen die niet bestaan of niet kunnen bestaan.
De oplossing van Picus is om het model verantwoordelijk te maken voor de coördinatie, niet voor de creatie.
In plaats van AI te vragen om payloads te schrijven, Picus’ agent BAS vergelijkt een nieuw dreigingsrapport met een samengestelde, vooraf gecontroleerde bibliotheek met veilige, kant-en-klare testbouwstenen. Een beveiligingsteam noemt een bedreiging, en a een multi-agentsysteem neemt het vanaf daar over: één agent identificeert de dreiging en stelt een onderzoeksplan op, anderen verzamelen en valideren de informatie uit meerdere bronnen, en een bouwagent brengt de vijandige TTP’s in kaart in aanvalsketens die klaar zijn voor simulatie.
De output is een nauwkeurige, kant-en-klare simulatie, samengesteld in enkele minuten.
Hierdoor stort de lus in. Een CISA-waarschuwing of een doorgestuurde kop wordt een scopetest, een houdingsscore, geprioriteerde oplossingen en een uitvoerend rapport, vaak binnen enkele minuten, waarbij mensen uitzonderingen beoordelen in plaats van elke stap te autorijden en te vertragen.
Dit is waar het Picus-platform voor is gebouwd
Patchen is nog steeds essentieel, maar waar AI duizenden fouten ontdekt en deze binnen enkele uren bewapent, kan patchen alleen niet de hele strategie zijn. Als de aanval autonoom is, moet de verdediging op zijn minst met dezelfde snelheid opereren, en dat is precies waarvoor Picus is gebouwd.
Wat meegroeit met de dreiging is validatie: bevestigen wat uw controles daadwerkelijk zullen tegenhouden, bewijzen wat exploiteerbaar is, en hersteltijd en talent alleen besteden daar waar dit de uitkomst zal veranderen. Door AI aangedreven, agentische BAS is een van de kernpijlers van het Picus Platformwaarbij je voortdurend test of je verdediging blokkeert en detecteert wat belangrijk is, zonder te wachten op een mens om het proces te starten of door te gaan naar de volgende cyclus. En wanneer er een gat wordt ontdekt, verwijst het platform naar de leverancierspecifieke oplossing die nodig is, en legt het niet zomaar een nieuw ticket op de stapel, maar valideert het vervolgens opnieuw om te bevestigen dat het gat daadwerkelijk is gedicht.
De noodzaak om ter plekke te zeggen of een nieuwe kop het bedrijf in gevaar brengt, zal niet snel verdwijnen. Het Picus Platform geeft beveiligingsteams antwoord voordat iemand erom vraagt.
Ontdek of de volgende kop u in gevaar brengt, voordat deze daalt. Vraag een demo aan.
Opmerking: dit artikel is geschreven door Sıla Özeren Hacıoğlu, Security Research Engineer bij Picus Security.