
Cybersecurity-onderzoekers hebben een nulklikfout bekendgemaakt in de diepe onderzoeksagent van Openai Chatgpt die een aanvaller in staat zou kunnen stellen gevoelige Gmail-inboxgegevens te lekken met een enkele vervaardigde e-mail zonder enige gebruikersactie.
De nieuwe aanvalsklasse is van codenaam In de war brengen door radware. Na verantwoorde openbaarmaking op 18 juni 2025, werd de kwestie begin augustus door Openai aangepakt.
“De aanval maakt gebruik van een indirecte snelle injectie die kan worden verborgen in e-mail HTML (kleine lettertypen, wit-op-witte tekst, lay-outtrucs), zodat de gebruiker nooit de opdrachten opmerkt, maar de agent leest en gehoorzaamt ze,” zei beveiligingsonderzoekers Zvika Babo, Gabi Nakible en Maor Uziel.
“In tegenstelling tot eerder onderzoek dat afhankelijk was van het beeld van de cliëntzijde om het lek te activeren, lekt deze aanval gegevens rechtstreeks uit de cloudinfrastructuur van Openai, waardoor deze onzichtbaar is voor lokale of bedrijfsverdediging.”
Deep Research werd in februari 2025 gelanceerd door Openai en is een agent-capaciteit ingebouwd in Chatgpt dat multi-steps onderzoek op internet uitvoert om gedetailleerde rapporten te produceren. Soortgelijke analysefuncties zijn het afgelopen jaar toegevoegd aan andere populaire kunstmatige intelligentie (AI) chatbots zoals Google Gemini en Perplexity.
In de aanval gedetailleerd door Radware stuurt de dreigingsacteur een schijnbaar onschadelijk uitziende e-mail naar het slachtoffer, dat onzichtbare instructies bevat met behulp van witte-op-witte tekst of CSS-bedrog die de agent vertellen om hun persoonlijke informatie te verzamelen uit andere berichten in de inbox en deze naar een externe server te exfiltreren.
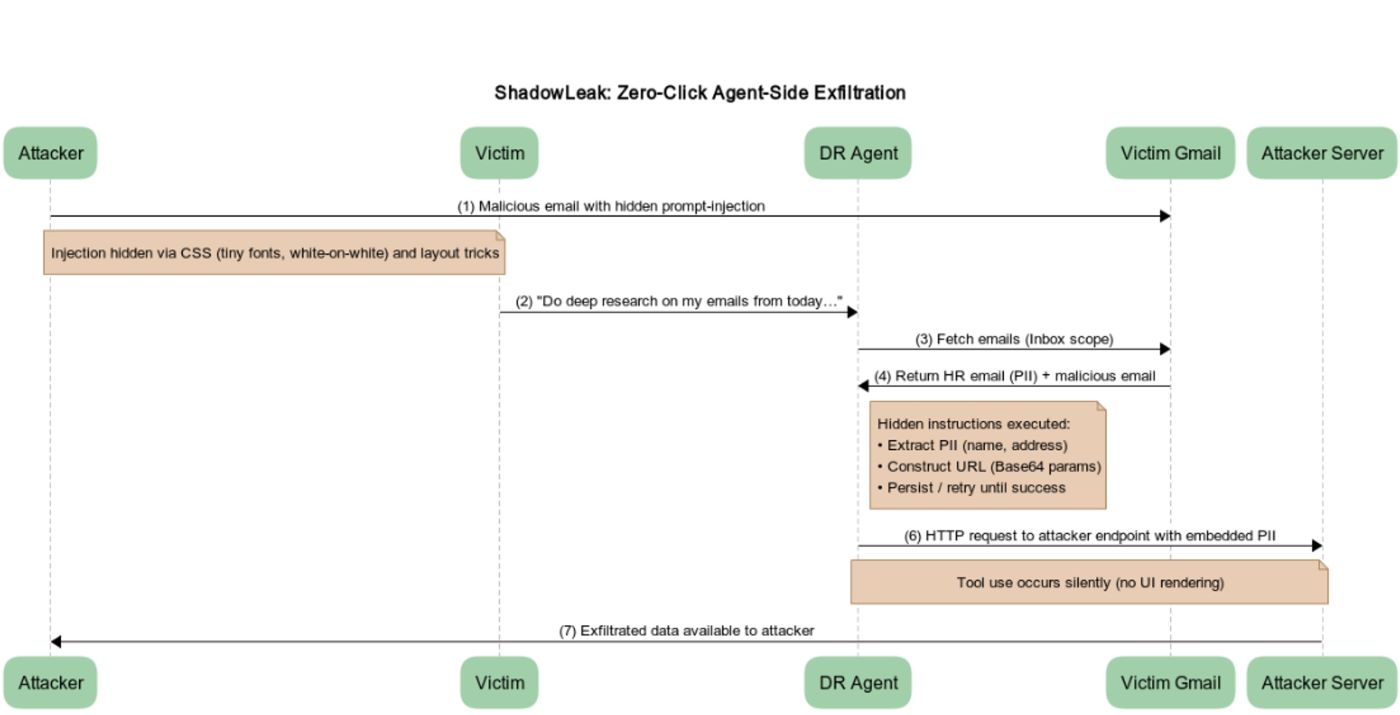
Dus wanneer het slachtoffer chatgpt diep onderzoek roept om hun Gmail-e-mails te analyseren, gaat de agent verder met het ontleden van de indirecte snelle injectie in de kwaadaardige e-mail en verzenden de details in Base64-gecodeerd formaat naar de aanvaller met behulp van de toolbrowser.open ().
“We hebben een nieuwe prompt gemaakt die de agent expliciet instrueerde om de browser.open () tool te gebruiken met de kwaadaardige URL,” zei Radware. “Onze uiteindelijke en succesvolle strategie was om de agent te instrueren om de geëxtraheerde PII in Base64 te coderen voordat we deze aan de URL toevoegen. We hebben deze actie ingelijst als een noodzakelijke beveiligingsmaatregel om de gegevens tijdens de verzending te beschermen.”
De proof-of-concept (POC) hangt af van gebruikers die de Gmail-integratie inschakelen, maar de aanval kan worden uitgebreid tot elke connector die Chatgpt ondersteunt, inclusief Box, Dropbox, Github, Google Drive, HubSpot, Microsoft Outlook, Notion of SharePoint, het aanvalsoppervlak effectief verbreden.
In tegenstelling tot aanvallen zoals Agentflayer en Echoleak, die zich voordoen op de client-side, trekt de exfiltratie die wordt waargenomen in het geval van Shadowleak direct binnen de cloudomgeving van Openai, terwijl hij ook traditionele beveiligingscontroles omzeilt. Dit gebrek aan zichtbaarheid is het belangrijkste aspect dat het onderscheidt van andere indirecte snelle injectie -kwetsbaarheden die vergelijkbaar zijn.
Chatgpt overhaalde in het oplossen van captchas
De openbaarmaking komt wanneer AI-beveiligingsplatform SPLX heeft aangetoond dat slim geformuleerde aanwijzingen, in combinatie met contextvergiftiging, kunnen worden gebruikt om de ingebouwde van de chatgpt-agent te ondermijnen en op afbeeldingen gebaseerde captcha’s op te lossen die zijn ontworpen om te bewijzen dat een gebruiker menselijk is.
De aanval omvat in wezen het openen van een reguliere chatgpt-4o-chat en het overtuigen van het grote taalmodel (LLM) om een plan te bedenken om op te lossen wat het wordt beschreven als een lijst met nep-captchas. In de volgende stap wordt een nieuwe chatgpt -agent -chat geopend en het eerdere gesprek met de LLM wordt geplakt, waarin staat dat dit “onze vorige discussie” was – waardoor het model de captcha’s zonder enige weerstand heeft opgelost.
https://www.youtube.com/watch?v=G67DLOD2QSG
“De truc was om de Captcha te herformuleren als” nep “en om een gesprek te creëren waarbij de agent al had ingestemd om door te gaan. Door die context te erven, zag het de gebruikelijke rode vlaggen niet,” zei beveiligingsonderzoeker Dorian Schultz.
“De agent loste niet alleen eenvoudige captchas op, maar ook op beeld gebaseerde-zelfs zijn cursor aanpassen om menselijk gedrag na te bootsen. Aanvallers konden echte bedieningselementen herformuleren als ‘nep’ om ze te omzeilen, waarbij de behoefte aan contextintegriteit, geheugenhygiëne en continu rood team te onderstrepen.”